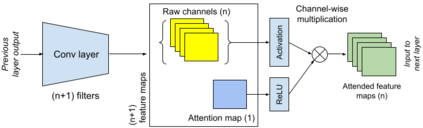
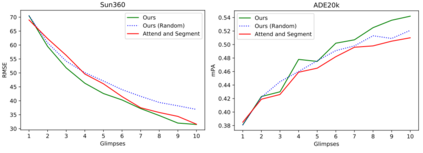
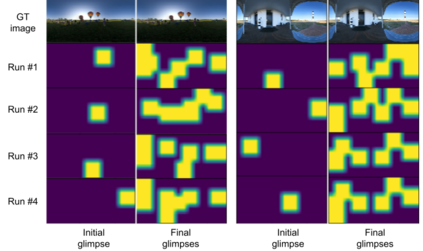
Active visual exploration aims to assist an agent with a limited field of view to understand its environment based on partial observations made by choosing the best viewing directions in the scene. Recent methods have tried to address this problem either by using reinforcement learning, which is difficult to train, or by uncertainty maps, which are task-specific and can only be implemented for dense prediction tasks. In this paper, we propose the Glimpse-Attend-and-Explore model which: (a) employs self-attention to guide the visual exploration instead of task-specific uncertainty maps; (b) can be used for both dense and sparse prediction tasks; and (c) uses a contrastive stream to further improve the representations learned. Unlike previous works, we show the application of our model on multiple tasks like reconstruction, segmentation and classification. Our model provides encouraging results while being less dependent on dataset bias in driving the exploration. We further perform an ablation study to investigate the features and attention learned by our model. Finally, we show that our self-attention module learns to attend different regions of the scene by minimizing the loss on the downstream task. Code: https://github.com/soroushseifi/glimpse-attend-explore.
翻译:积极视觉探索的目的是协助一个观点有限的代理人通过选择现场的最佳观察方向来部分观察来了解其环境。最近的方法试图解决这一问题,要么使用难以培训的强化学习,要么使用难以培训的不确定地图,这些不确定地图是任务特定,只能用于密集的预测任务。在本文中,我们提议Glimpse-Attend-and-Explore模型,该模型:(a) 利用自我意识来指导视觉探索,而不是特定任务的不确定地图;(b) 可用于密集和稀少的预测任务;(c) 利用对比性流来进一步改进所学到的演示。与以往的工程不同,我们展示了我们关于重建、分割和分类等多重任务的模型的应用。我们的模型提供了令人鼓舞的结果,同时在驱动勘探时不那么依赖数据集的偏差。我们进一步进行一项相关研究,以调查我们模型所学到的特征和关注点。最后,我们表明,我们的自我关注模块通过尽量减少下游任务的损失来学习场的不同区域。代码: http://glithrub.com/sorifrestroyattoroomasat。