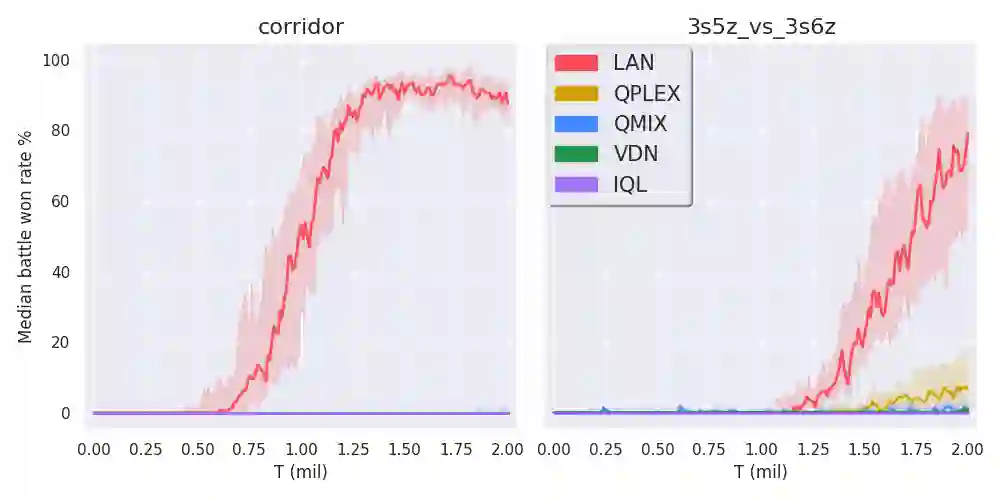
Multi-agent reinforcement learning (MARL) enables us to create adaptive agents in challenging environments, even when the agents have limited observation. Modern MARL methods have focused on finding factorized value functions. While successful, the resulting methods have convoluted network structures. We take a radically different approach and build on the structure of independent Q-learners. Our algorithm LAN leverages a dueling architecture to represent decentralized policies as separate individual advantage functions w.r.t.\ a centralized critic that is cast aside after training. The critic works as a stabilizer that coordinates the learning and to formulate DQN targets. This enables LAN to keep the number of parameters of its centralized network independent in the number of agents, without imposing additional constraints like monotonic value functions. When evaluated on the SMAC, LAN shows SOTA performance overall and scores more than 80\% wins in two super-hard maps where even QPLEX does not obtain almost any wins. Moreover, when the number of agents becomes large, LAN uses significantly fewer parameters than QPLEX or even QMIX. We thus show that LAN's structure forms a key improvement that helps MARL methods remain scalable.
翻译:多剂强化学习(MARL)使我们得以在具有挑战性的环境中创造适应性剂,即使代理商观察有限。现代MARL方法侧重于寻找要素化价值功能。现代MARL方法虽然成功,但有助于找到要素化价值功能。由此产生的方法具有复杂的网络结构。我们采取了完全不同的方法,并依靠独立的Q-learners的结构。我们的局域网算法利用分权结构代表分散政策,作为单独的个人优势函数 w.r.t.\,在培训后被搁置的集中评论家。评论家作为一个稳定器,协调学习和制定DQN目标。这使得局域网能够保持其集中网络参数的数量在代理器数量上独立,而不会像单调值功能那样施加额外的限制。在对SMAC进行评价时,局域网显示SOTA的总体业绩,在两张超级硬地图中赢得了80多分,而即使QPLEX也几乎得不到任何优势。此外,当药剂数量大时,局网域网使用的参数大大少于QPLEX或QMIX。因此,我们显示局网的结构构成关键的改进是能够帮助MAL的方法。