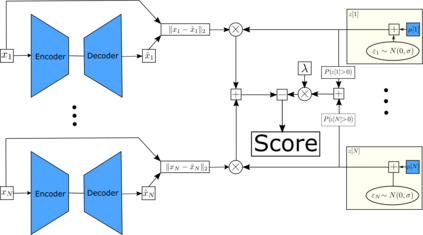
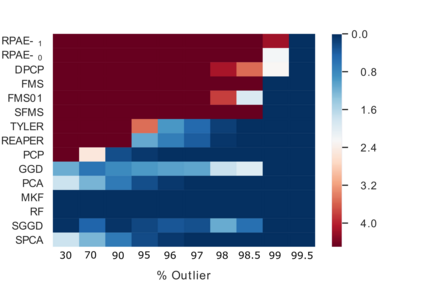
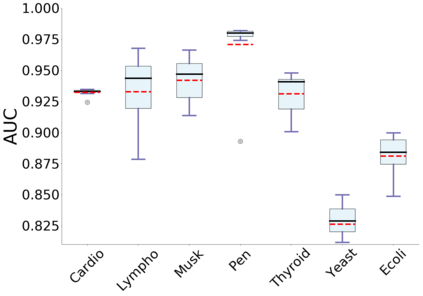
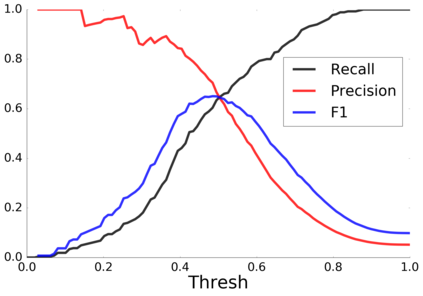
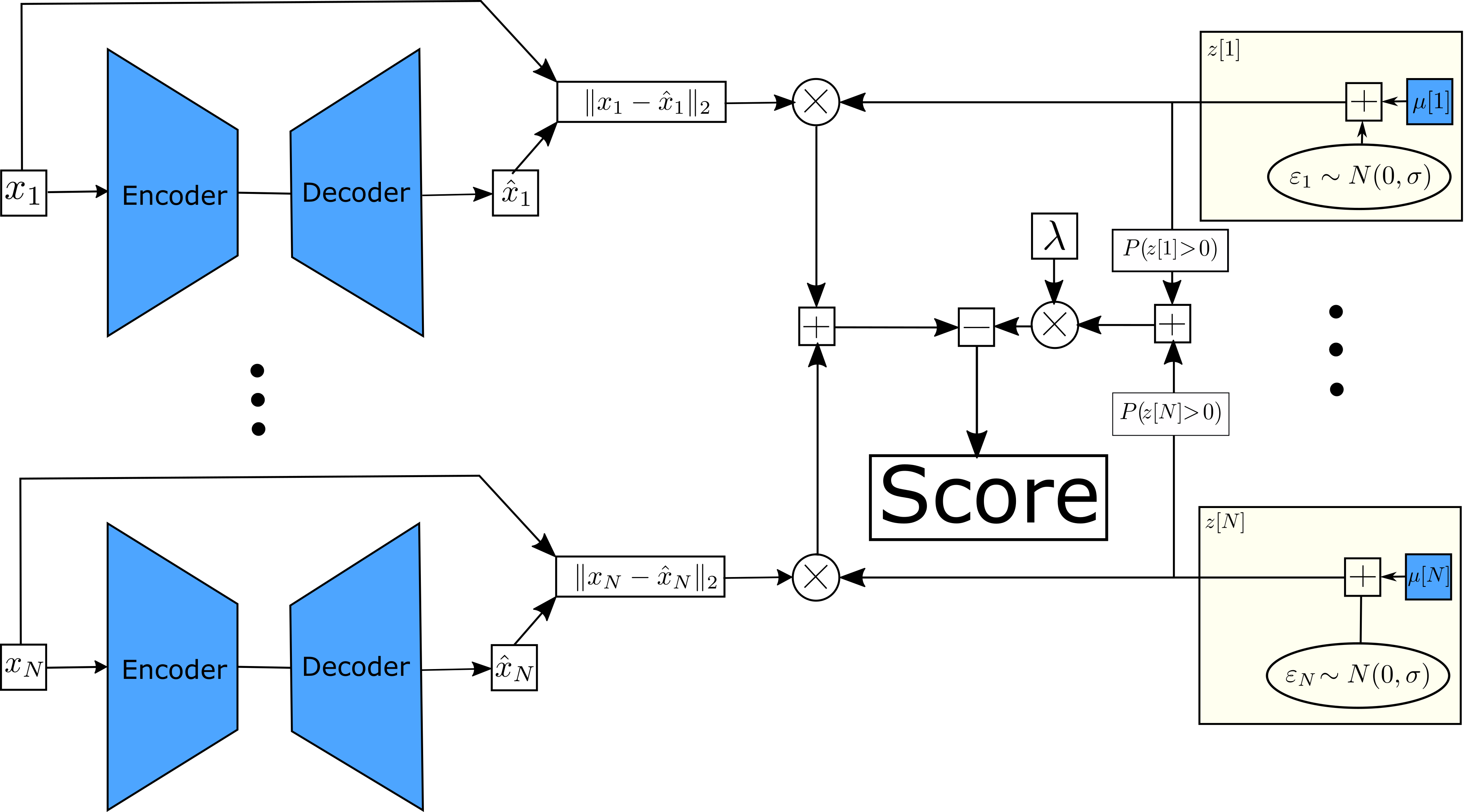
Empirical observations often consist of anomalies (or outliers) that contaminate the data. Accurate identification of anomalous samples is crucial for the success of downstream data analysis tasks. To automatically identify anomalies, we propose a new type of autoencoder (AE) which we term Probabilistic Robust autoencoder (PRAE). PRAE is designed to simultaneously remove outliers and identify a low-dimensional representation for the inlier samples. We first describe Robust AE (RAE) as a model that aims to split the data to inlier samples from which a low dimensional representation is learned via an AE, and anomalous (outlier) samples that are excluded as they do not fit the low dimensional representation. Robust AE minimizes the reconstruction of the AE while attempting to incorporate as many observations as possible. This could be realized by subtracting from the reconstruction term an $\ell_0$ norm counting the number of selected observations. Since the $\ell_0$ norm is not differentiable, we propose two probabilistic relaxations for the RAE approach and demonstrate that they can effectively identify anomalies. We prove that the solution to PRAE is equivalent to the solution of RAE and demonstrate using extensive simulations that PRAE is at par with state-of-the-art methods for anomaly detection.
翻译:经验观测通常包括污染数据的异常(或外部),准确识别异常样本对于下游数据分析任务的成功至关重要。为了自动识别异常,我们建议了一种新型自动编码器(AE),我们称之为“概率机器人自动编码器(PRAE) ” 。PRAE旨在同时去除外部源,并找出隐性样本的低维代表值。我们首先将Robust AE(RAE)描述为一种模型,目的是将数据分解为通过 AE 学习低维度代表的离子样本,而异常(外部)样本则被排除,因为它们不适合低维度代表值。Robust AE尽可能减少对自动编码器的重建,同时尽量纳入尽可能多的观察。这可以通过从重建期中减去计算选定观测次数的$\ell_0美元标准来实现。由于$\ell_0美元标准是不可更改的,我们建议两种相对等值的样本(AE)样本(AREE)排除,因为它们不符合低维度代表值。Robuste ADE 的解算法是用来有效证明对RAE 的解算法。