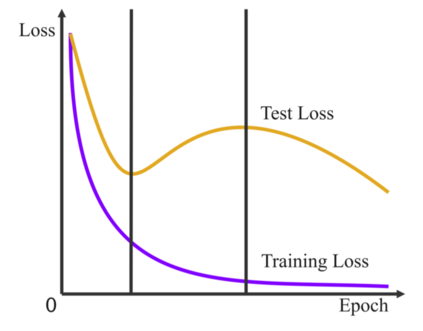
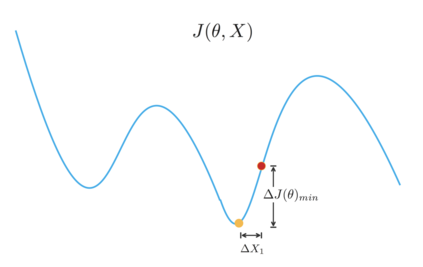
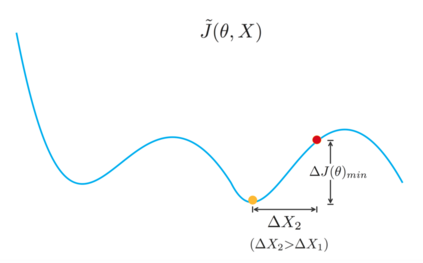
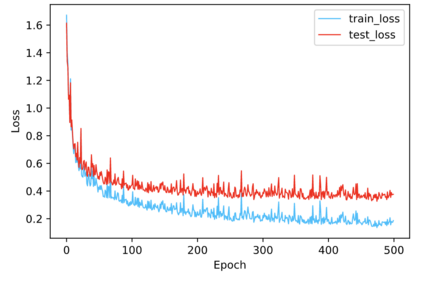
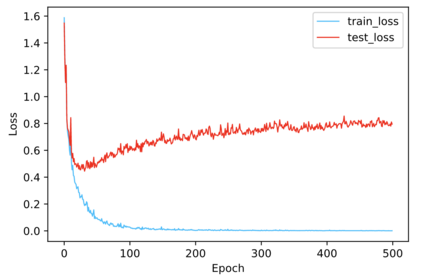
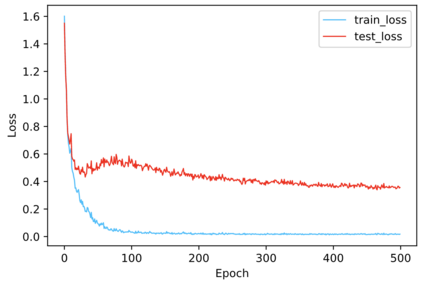
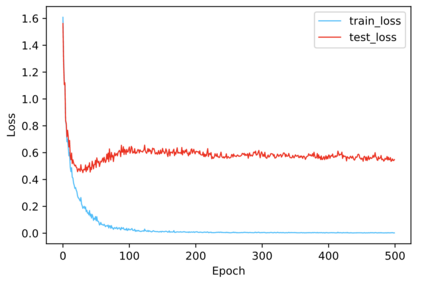
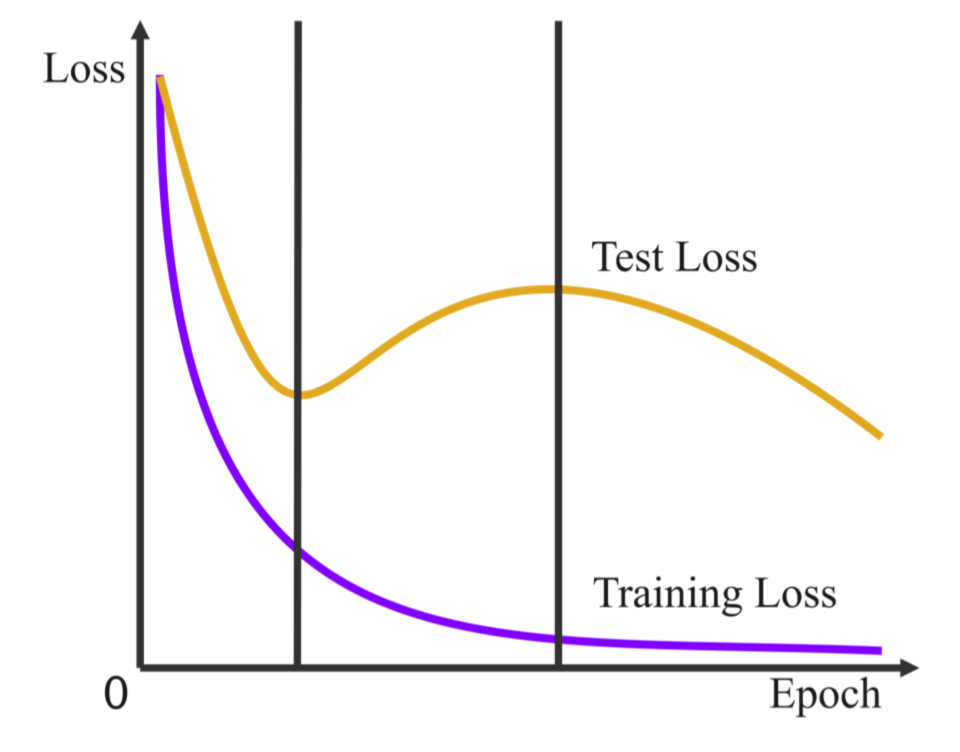
Regularization plays a vital role in machine learning optimization. One novel regularization method called flooding makes the training loss fluctuate around the flooding level. It intends to make the model continue to random walk until it comes to a flat loss landscape to enhance generalization. However, the hyper-parameter flooding level of the flooding method fails to be selected properly and uniformly. We propose a novel method called Jitter to improve it. Jitter is essentially a kind of random loss function. Before training, we randomly sample the Jitter Point from a specific probability distribution. The flooding level should be replaced by Jitter point to obtain a new target function and train the model accordingly. As Jitter point acting as a random factor, we actually add some randomness to the loss function, which is consistent with the fact that there exists innumerable random behaviors in the learning process of the machine learning model and is supposed to make the model more robust. In addition, Jitter performs random walk randomly which divides the loss curve into small intervals and then flipping them over, ideally making the loss curve much flatter and enhancing generalization ability. Moreover, Jitter can be a domain-, task-, and model-independent regularization method and train the model effectively after the training error reduces to zero. Our experimental results show that Jitter method can improve model performance more significantly than the previous flooding method and make the test loss curve descend twice.
翻译:在机器学习优化中, 常规化具有关键作用 。 一种叫洪水的新颖的正规化方法, 叫做“ 洪水”, 使培训损失在洪水水平上波动。 它打算让模型继续随机行走, 直至形成一个平坦的损失景观, 以强化概括化。 但是, 洪涝方法的超参数洪涝水平没有被正确和统一地选择。 我们提议了一个叫作 Jitter 的新型方法来改进它。 Jitter 基本上是一种随机丢失功能。 在培训之前, 我们随机地从特定的概率分布中抽取Jitter Point 。 洪水水平应该由 Jitter 点取代, 以获得一个新的目标函数并相应培训模型。 作为随机因素, 我们实际上会给损失函数添加一些随机性, 以强化总体化能力 。 与机器学习模型中存在无数随机行为的事实一致, 我们提议了一个叫Jitter 随机行走,, 将损失曲线分成一个小间隔, 然后翻转, 理想的是让损失曲线曲线变得非常贴, 并增强一般化能力 。 此外, Jitter 可以成为一个域、任务、 和模型化的模型化方法, 能够有效地降低我们之前的模型, 的模型和模型化方法。