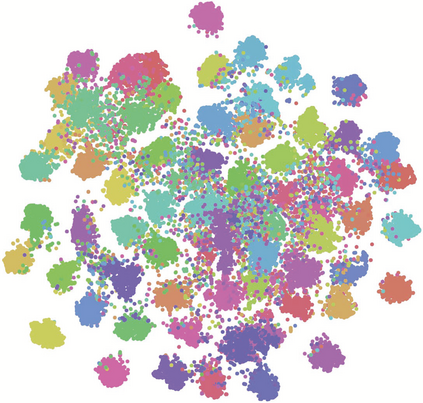
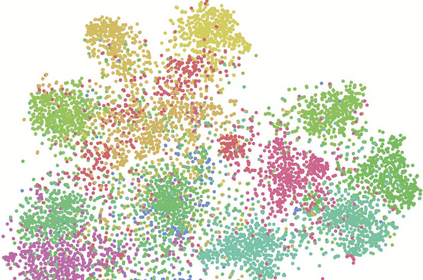
Few-shot learning is a challenging task, which aims to learn a classifier for novel classes with few labeled samples. Previous studies mainly focus on two-phase meta-learning methods. Recently, researchers find that introducing an extra pre-training phase can significantly improve the performance. The key idea is to learn a feature extractor with pre-training and then fine-tune it through the nearest centroid based meta-learning. However, results show that the fine-tuning step makes very marginal improvements. We thus argue that the current meta-learning scheme does not fully explore the power of the pre-training. The reason roots in the fact that in the pre-trained feature space, the base classes already form compact clusters while novel classes spread as groups with large variances. In this case, fine-tuning the feature extractor is less meaningful than estimating more representative prototypes. However, making such an estimation from few labeled samples is challenging because they may miss representative attribute features. In this paper, we propose a novel prototype completion based meta-learning framework. The framework first introduces primitive knowledge (i.e., class-level attribute or part annotations) and extracts representative attribute features as priors. A prototype completion network is then designed to learn to complement the missing attribute features with the priors. Finally, we develop a Gaussian based prototype fusion strategy to combine the mean-based and the complemented prototypes, which can effectively exploit the unlabeled samples. Extensive experimental results on three real-world data sets demonstrate that our method: (i) can obtain more accurate prototypes; (ii) outperforms state-of-the-art techniques by 2% - 9% on classification accuracy.
翻译:少见的学习是一项具有挑战性的任务,目的是学习具有少数标签样本的新类的分类。 先前的研究主要侧重于两阶段的元学习方法。 最近, 研究人员发现, 引入额外的培训前阶段可以大大改善业绩。 关键的想法是学习一个带有训练前的特性提取器, 然后通过最近的以机器人为基础的元学习来微调它。 但是, 结果显示微调步骤的改进非常微小。 我们因此认为, 目前的元学习计划没有完全探索训练前阶段的实力。 原因的根源在于, 在培训前的功能空间中, 基础类已经形成缩缩略式组合, 而新颖的分类则以大差异的组形式传播。 在此情况下, 微调特性提取器比估算更具代表性的原型要少一些。 但是, 从少数贴标签的样本中作出这样的估计是困难的, 因为他们可能错失了具有代表性的属性。 我们在此文件中, 我们提议一个基于新颖的模型完成模式, 补充了原始知识( 即, 类级属性或部分说明), 并提取有代表性的原型的原型特性特性特性, 。 最后, 将一个原型网络与前的原型模型结合起来, 我们所设计的原型模型进行。