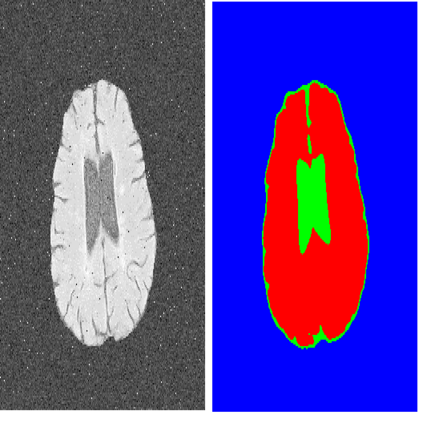
Manual annotation of medical images is highly subjective, leading to inevitable and huge annotation biases. Deep learning models may surpass human performance on a variety of tasks, but they may also mimic or amplify these biases. Although we can have multiple annotators and fuse their annotations to reduce stochastic errors, we cannot use this strategy to handle the bias caused by annotators' preferences. In this paper, we highlight the issue of annotator-related biases on medical image segmentation tasks, and propose a Preference-involved Annotation Distribution Learning (PADL) framework to address it from the perspective of disentangling an annotator's preference from stochastic errors using distribution learning so as to produce not only a meta segmentation but also the segmentation possibly made by each annotator. Under this framework, a stochastic error modeling (SEM) module estimates the meta segmentation map and average stochastic error map, and a series of human preference modeling (HPM) modules estimate each annotator's segmentation and the corresponding stochastic error. We evaluated our PADL framework on two medical image benchmarks with different imaging modalities, which have been annotated by multiple medical professionals, and achieved promising performance on all five medical image segmentation tasks.
翻译:医学图象的手工描述非常主观, 会导致不可避免和巨大的批注偏差。 深层次学习模型可能超过人类在各种任务方面的表现, 但是它们也可能模仿或放大这些偏差。 虽然我们可以有多个批注器并结合其说明以减少分解错误, 但我们不能使用这一战略来处理由批注者偏好造成的偏差。 在本文中, 我们强调与批注者相关的医学图片分解任务偏差问题, 并提议一个参考- 与批注分配学习( PADL) 框架, 以便从分解一个批注者偏好于通过分发学习产生分解错误的角度解决这个问题, 以便不仅产生元分解, 而且还能结合每个批注者可能作出的分解。 在此框架内, 一个随机误差模型( SEM) 模块估计了元分解图和平均分解错误地图的偏差, 并提出一系列人类偏好模型( HPPM) 框架, 来评估每个批注员的分解和对应的分解错误。 我们评估了我们PADL 的图象师偏差分解师的偏差选择框架, 通过两个医学图象学模型, 都用了两种不同的医学图象学模型模型,, 我们评估了两种不同的医学图象化模型的图解模式, 实现了了所有的图象学模型, 。