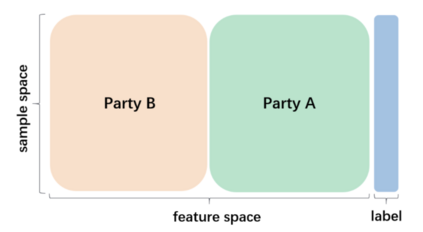
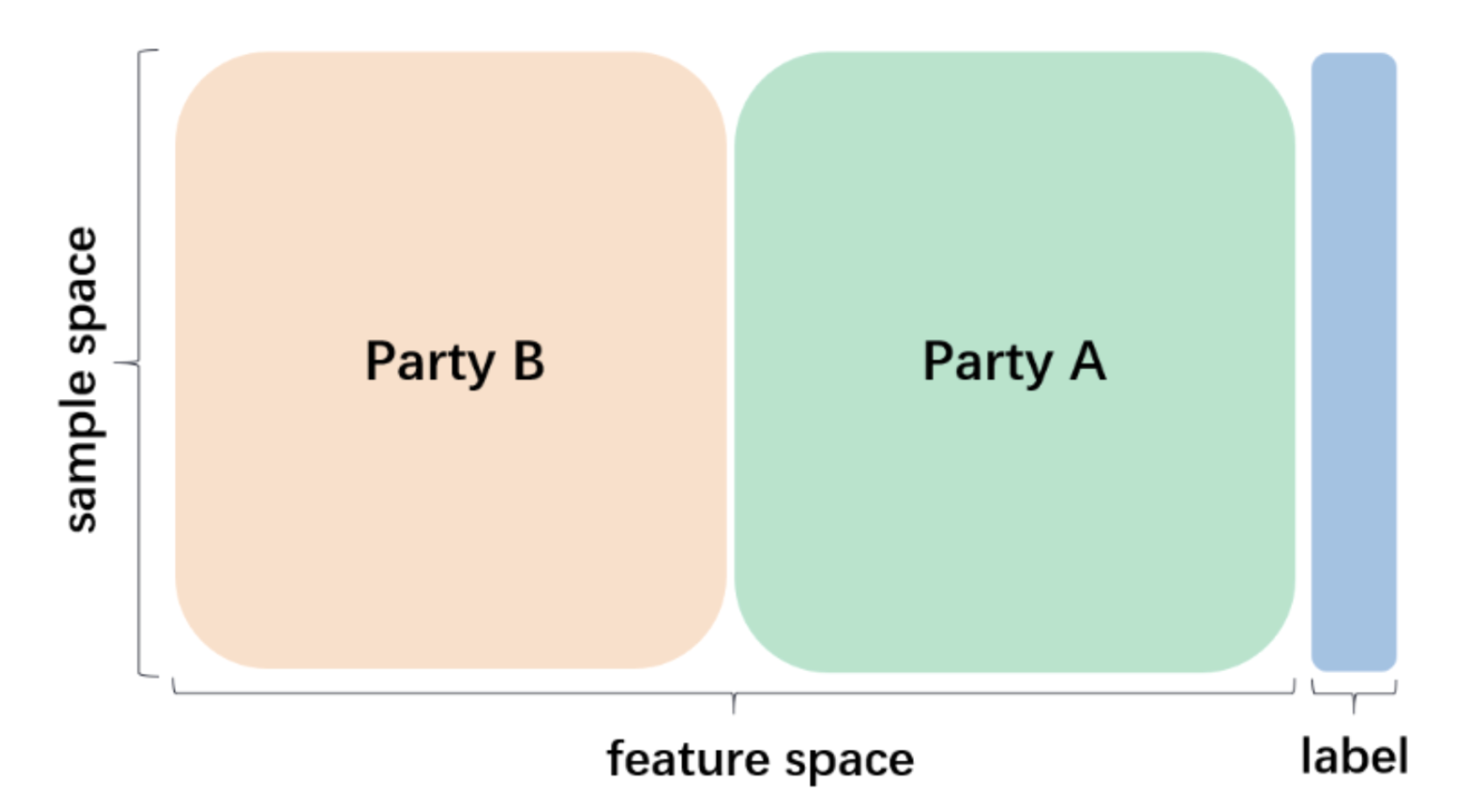
Human data forms the backbone of machine learning. Data protection laws thus have strong bearing on how ML systems are governed. Given that most requirements in data protection laws accompany the processing of personal data, organizations have an incentive to keep their data out of legal scope. This makes the development and application of certain privacy-preserving techniques--data protection techniques--an important strategy for ML compliance. In this paper, we examine the impact of a rhetoric that deems data wrapped in these techniques as data that is "good-to-go". We show how their application in the development of ML systems--from private set intersection as part of dataset curation to homomorphic encryption and federated learning as part of model computation--can further support individual monitoring and data consolidation. With data accumulation at the core of how the ML pipeline is configured, we argue that data protection techniques are often instrumentalized in ways that support infrastructures of surveillance, rather than in ways that protect individuals associated with data. Finally, we propose technology and policy strategies to evaluate data protection techniques in light of the protections they actually confer. We conclude by highlighting the role that technologists might play in devising policies that combat surveillance ML technologies.
翻译:暂无翻译