
Optimal usage of the memory system is a key element of fast GPU algorithms. Unfortunately many common algorithms fail in this regard despite exhibiting great regularity in memory access patterns. In this paper we propose efficient kernels to permute the elements of an array, which can be used to improve the access patterns of many algorithms. We handle a class of permutations known as Bit Matrix Multiply Complement (BMMC) permutations, for which we design kernels of speed comparable to that of a simple array copy. This is a first step towards implementing a set of array combinators based on these permutations.
翻译:暂无翻译

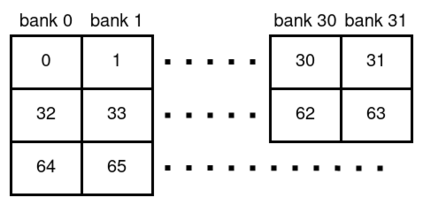
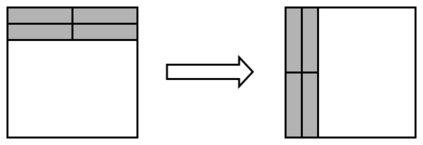
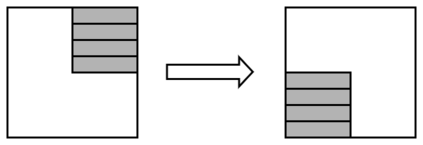

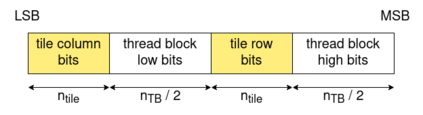



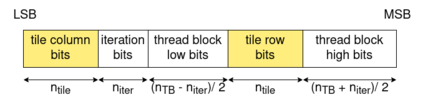





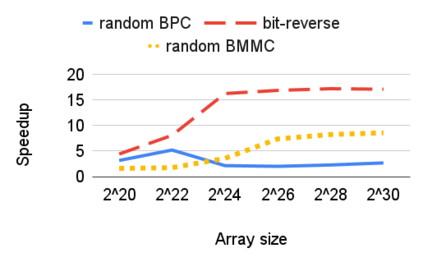
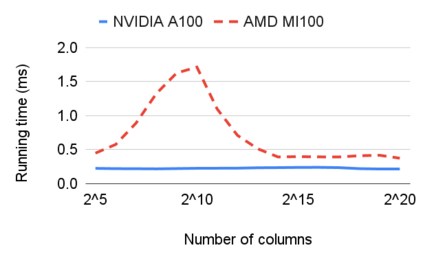


相关内容

专知会员服务
36+阅读 · 2019年10月17日
Arxiv
0+阅读 · 2023年8月3日
Arxiv
0+阅读 · 2023年8月2日


相关VIP内容
专知会员服务
36+阅读 · 2019年10月17日
相关资讯
相关论文
Arxiv
0+阅读 · 2023年8月3日
Arxiv
0+阅读 · 2023年8月2日