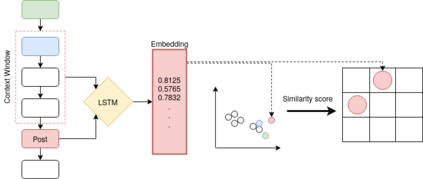
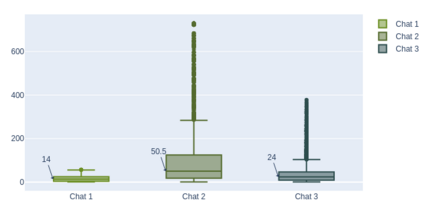
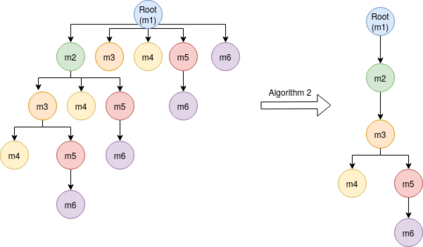
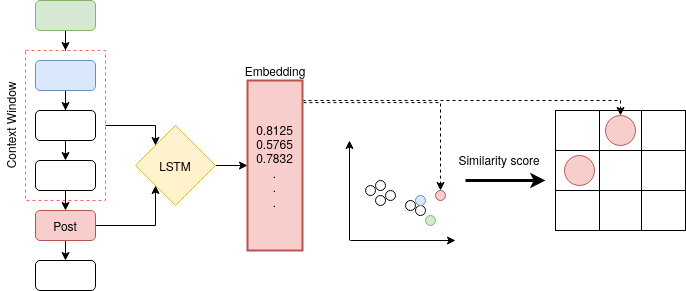
Most online message threads inherently will be cluttered and any new user or an existing user visiting after a hiatus will have a difficult time understanding whats being discussed in the thread. Similarly cluttered responses in a message thread makes analyzing the messages a difficult problem. The need for disentangling the clutter is much higher when the platform where the discussion is taking place does not provide functions to retrieve reply relations of the messages. This introduces an interesting problem to which \cite{wang2011learning} phrases as a structural learning problem. We create vector embeddings for posts in a thread so that it captures both linguistic and positional features in relation to a context of where a given message is in. Using these embeddings for posts we compute a similarity based connectivity matrix which then converted into a graph. After employing a pruning mechanisms the resultant graph can be used to discover the reply relation for the posts in the thread. The process of discovering or disentangling chat is kept as an unsupervised mechanism. We present our experimental results on a data set obtained from Telegram with limited meta data.
翻译:大部分在线信息线索本身将被分解, 任何新用户或现有用户在断线后访问时会很难理解线索中讨论的内容。 同样, 线索中被分解的回复会给分析信息带来困难。 当讨论所在的平台没有提供检索信件回复关系的功能时, 解开线条的必要性要高得多 。 这引入了一个有趣的问题, 使\ cite{ wang2011} 的词句成为结构性学习问题 。 我们为线条中的插件创建矢量嵌入器, 以便它能够捕捉到与给定信件所在背景有关的语言和位置特性。 使用这些嵌入器, 我们为这些基于类似连接的矩阵进行计算, 然后转换成图表 。 在使用剪裁机制后, 结果图可以用来发现线条中文章的回复关系 。 发现或断线条聊天的过程将保留为不受监控的机制 。 我们用有限的元数据在从Telegram获得的数据集上展示我们的实验结果 。