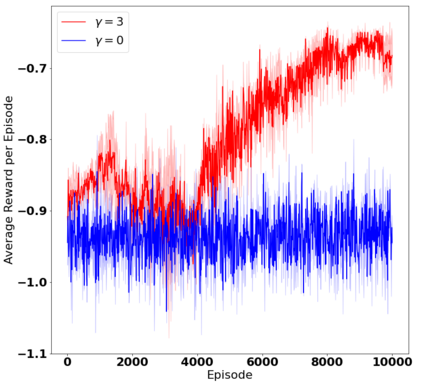
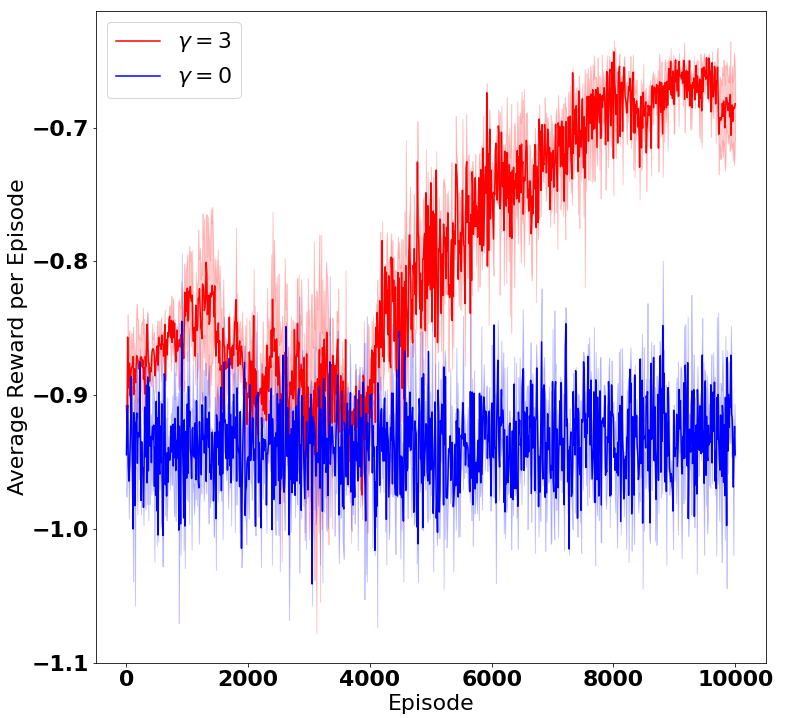
A challenge in reinforcement learning (RL) is minimizing the cost of sampling associated with exploration. Distributed exploration reduces sampling complexity in multi-agent RL (MARL). We investigate the benefits to performance in MARL when exploration is fully decentralized. Specifically, we consider a class of online, episodic, tabular $Q$-learning problems under time-varying reward and transition dynamics, in which agents can communicate in a decentralized manner.We show that group performance, as measured by the bound on regret, can be significantly improved through communication when each agent uses a decentralized message-passing protocol, even when limited to sending information up to its $\gamma$-hop neighbors. We prove regret and sample complexity bounds that depend on the number of agents, communication network structure and $\gamma.$ We show that incorporating more agents and more information sharing into the group learning scheme speeds up convergence to the optimal policy. Numerical simulations illustrate our results and validate our theoretical claims.
翻译:强化学习(RL)的一个挑战是最大限度地降低与勘探有关的取样成本。分布式勘探会降低多试剂RL(MARL)的取样复杂性。当勘探完全分散时,我们调查MARL对业绩的好处。具体地说,我们考虑在时间变化的奖励和过渡动态下,一种在线的、附带的、以美元计价的学习问题,使代理商能够以分散的方式进行交流。我们表明,如果每个代理商使用分散式的传递信息协议,即使仅限于向它的近邻发送信息,则群体业绩可以通过通信得到显著改善。我们证明,根据代理商的数量、通信网络结构和$\gamma.美元,我们证明了遗憾和抽样的复杂性界限,这些界限取决于代理商的数量、通信网络结构和$\gamma.美元。我们表明,将更多的代理商和更多的信息共享纳入集体学习计划可以加快与最佳政策的趋同。数字模拟可以说明我们的结果并验证我们的理论主张。