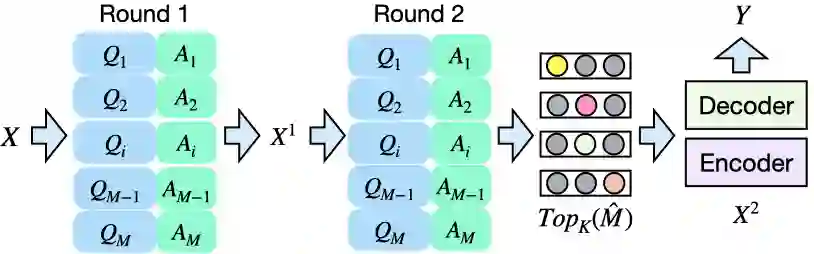
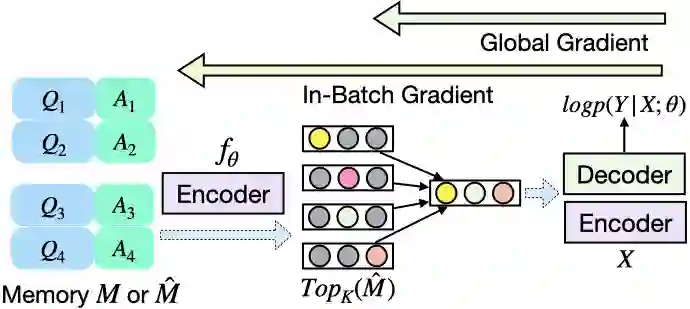
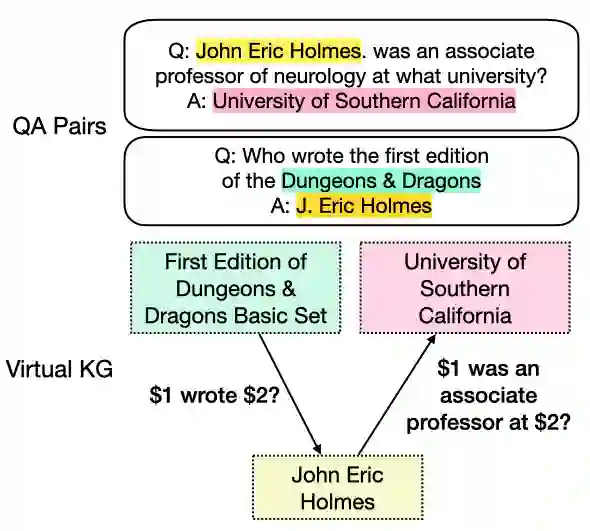
Retrieval augmented language models have recently become the standard for knowledge intensive tasks. Rather than relying purely on latent semantics within the parameters of large neural models, these methods enlist a semi-parametric memory to encode an index of knowledge for the model to retrieve over. Most prior work has employed text passages as the unit of knowledge, which has high coverage at the cost of interpretability, controllability, and efficiency. The opposite properties arise in other methods which have instead relied on knowledge base (KB) facts. At the same time, more recent work has demonstrated the effectiveness of storing and retrieving from an index of Q-A pairs derived from text \citep{lewis2021paq}. This approach yields a high coverage knowledge representation that maintains KB-like properties due to its representations being more atomic units of information. In this work we push this line of research further by proposing a question-answer augmented encoder-decoder model and accompanying pretraining strategy. This yields an end-to-end system that not only outperforms prior QA retrieval methods on single-hop QA tasks but also enables compositional reasoning, as demonstrated by strong performance on two multi-hop QA datasets. Together, these methods improve the ability to interpret and control the model while narrowing the performance gap with passage retrieval systems.
翻译:重新获取增强的语言模型最近已成为知识密集型任务的标准。 这些方法不是完全依靠大型神经模型参数范围内的潜在语义学,而是利用半参数内存来编码模型要检索的知识索引。 大部分以前的工作都采用文本段落作为知识单位, 以可解释性、可控性和效率为代价, 其覆盖面高, 以可理解性、 可控性和效率为代价。 相反的特性出现在其他方法中, 而这些方法则以知识基础( KB) 事实为根据。 与此同时, 较近期的工作表明, 从文本 \ citep{ lewis2021paq} 衍生的Q-A配对索引中存储和检索的功效。 这种方法产生了一个高覆盖面的知识代表, 保持KB相似的属性, 因为它的表达方式是更多的原子信息单位。 在这项工作中,我们进一步推进了这一研究线,方法是提出一个问题解答, 增强编码解析模式和伴随的培训前战略。 这产生了一个端到端系统,不仅超越了以前从文本 QA 双检索方法, 改进了单一QA 能力分析系统, 改进了业绩分析方法, 也使业绩分析了这些系统得以进行更精确分析。