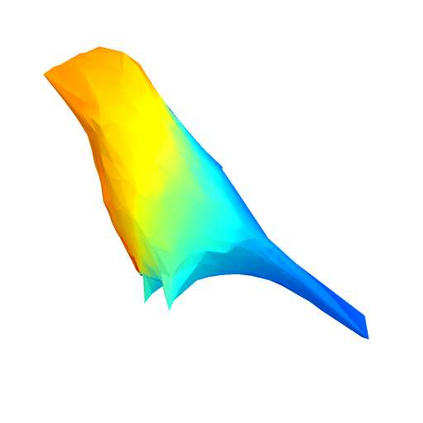
We propose a novel framework for fine-grained object recognition that learns to recover object variation in 3D space from a single image, trained on an image collection without using any ground-truth 3D annotation. We accomplish this by representing an object as a composition of 3D shape and its appearance, while eliminating the effect of camera viewpoint, in a canonical configuration. Unlike conventional methods modeling spatial variation in 2D images only, our method is capable of reconfiguring the appearance feature in a canonical 3D space, thus enabling the subsequent object classifier to be invariant under 3D geometric variation. Our representation also allows us to go beyond existing methods, by incorporating 3D shape variation as an additional cue for object recognition. To learn the model without ground-truth 3D annotation, we deploy a differentiable renderer in an analysis-by-synthesis framework. By incorporating 3D shape and appearance jointly in a deep representation, our method learns the discriminative representation of the object and achieves competitive performance on fine-grained image recognition and vehicle re-identification. We also demonstrate that the performance of 3D shape reconstruction is improved by learning fine-grained shape deformation in a boosting manner.
翻译:我们提出一个微微放大天体识别新框架,它能够从单一图像中恢复3D空间的物体变异,在不使用任何地面真象 3D 注释的情况下接受图像收集培训。我们通过将一个物体作为3D形状及其外观的组合来代表一个3D形状和外观,同时消除摄像观点的效果,用一种粗体结构来消除摄像观点的效果。与仅以 2D 图像为空间变异模型建模的常规方法不同,我们的方法能够将3D 图像的外观特征重新配置为3D 空间,从而使随后的物体分类者能够在3D 几何变形变异状态下进行。我们的代表还允许我们超越现有方法,将3D 形状变异作为物体识别的附加提示。要学习不使用地面真象 3D 注释的模型,我们在分析合成图象框架中设置了一个不同的成型。我们的方法通过将3D 形状的变形和外观结合到深度的外观,可以学习该物体的有区别的表达方式,并在3D 图像识别和车辆再定位上取得竞争性的性表现。我们还展示了3D 改进了3D 的变形的形状的形状的形状的变形。