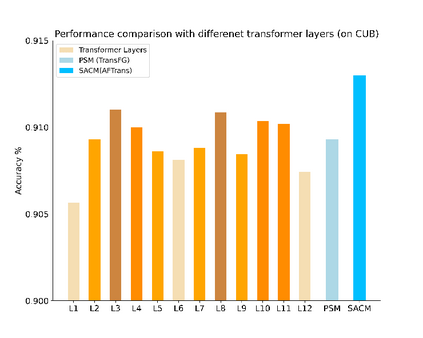
Learning subtle representation about object parts plays a vital role in fine-grained visual recognition (FGVR) field. The vision transformer (ViT) achieves promising results on computer vision due to its attention mechanism. Nonetheless, with the fixed size of patches in ViT, the class token in deep layer focuses on the global receptive field and cannot generate multi-granularity features for FGVR. To capture region attention without box annotations and compensate for ViT shortcomings in FGVR, we propose a novel method named Adaptive attention multi-scale Fusion Transformer (AFTrans). The Selective Attention Collection Module (SACM) in our approach leverages attention weights in ViT and filters them adaptively to correspond with the relative importance of input patches. The multiple scales (global and local) pipeline is supervised by our weights sharing encoder and can be easily trained end-to-end. Comprehensive experiments demonstrate that AFTrans can achieve SOTA performance on three published fine-grained benchmarks: CUB-200-2011, Stanford Dogs and iNat2017.
翻译:视觉变压器(ViT)因其关注机制,在计算机视觉方面取得了有希望的成果。然而,由于ViT中的补丁的固定大小,深层的级标牌侧重于全球可接受字段,不能为FGVR产生多色特征。为了在FGVR中不插框注解注而引起区域注意,并弥补ViT的缺陷,我们提议了一种名为适应性关注多级融合变压器(AFT)的新方法。在我们的方法中,选择性关注收集模块(SACM)在维特中利用了关注权重,并根据投入补丁的相对重要性进行过滤。多层(全球和地方)管道由我们共享电码器的重量监督,可以很容易地经过培训的终端到终端。全面实验表明,AFTRT能够以三种已公布的精细基准(CUB-200-2011年、斯坦福狗和iNat2017年)实现SOTA的绩效。