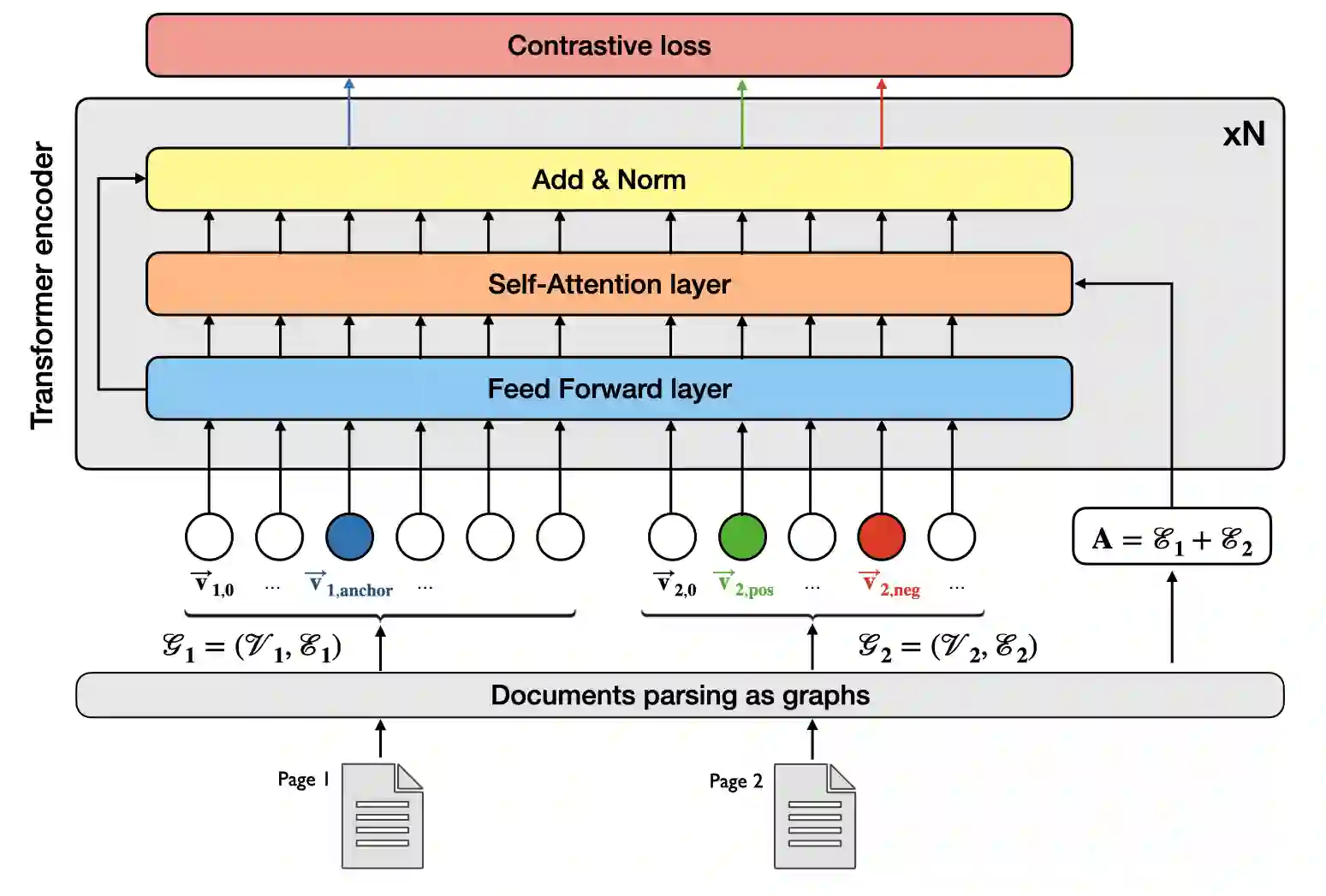
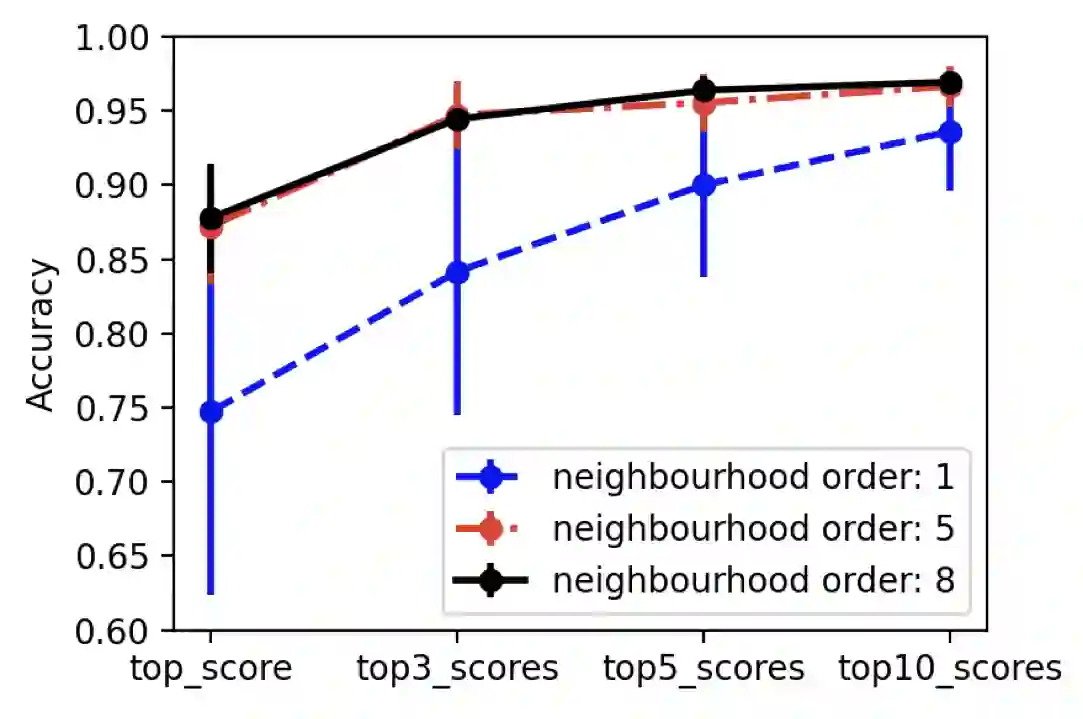
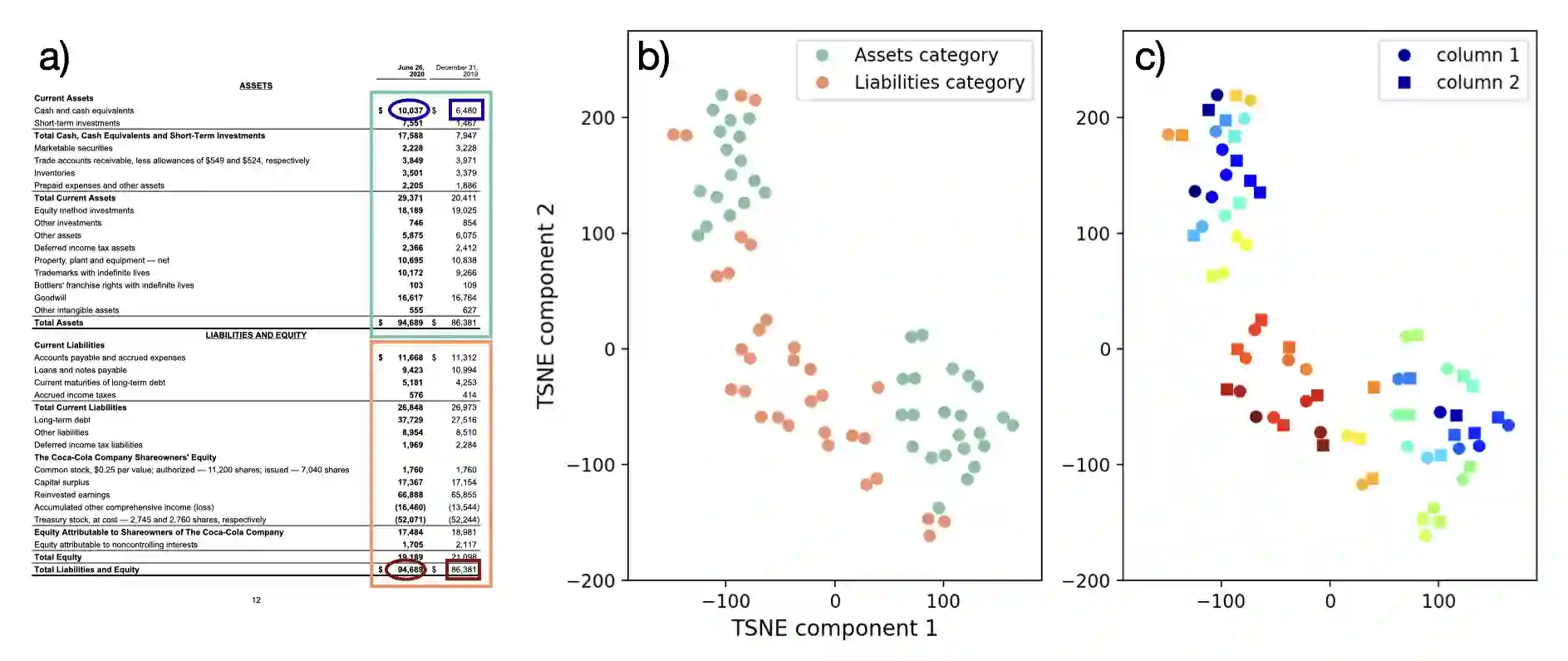
Representing structured text from complex documents typically calls for different machine learning techniques, such as language models for paragraphs and convolutional neural networks (CNNs) for table extraction, which prohibits drawing links between text spans from different content types. In this article we propose a model that approximates the human reading pattern of a document and outputs a unique semantic representation for every text span irrespective of the content type they are found in. We base our architecture on a graph representation of the structured text, and we demonstrate that not only can we retrieve semantically similar information across documents but also that the embedding space we generate captures useful semantic information, similar to language models that work only on text sequences.
翻译:代表来自复杂文件的结构化文本通常需要不同的机器学习技术,例如段落的语言模型和用于表格提取的进化神经网络(CNNs)等,禁止从不同内容类型中绘制文本之间的链接;在本条中,我们提出了一个模型,以接近文件和产出的人文阅读模式为近似,对每个文本的表达方式都是一种独特的语义表达方式,而不论其内容类型如何。我们以结构化文本的图表表达方式为基础构建我们的架构,并且我们证明,我们不仅能够检索到跨文件的语义相似的信息,而且我们生成的嵌入空间能够捕捉有用的语义信息,类似于仅对文本顺序起作用的语言模式。