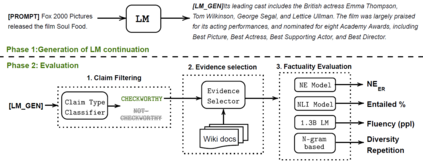
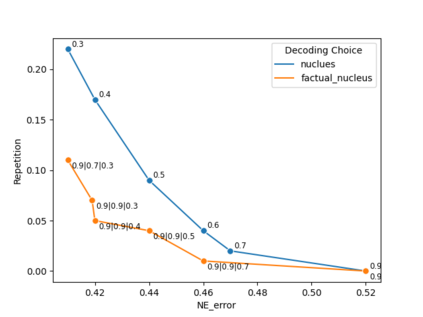
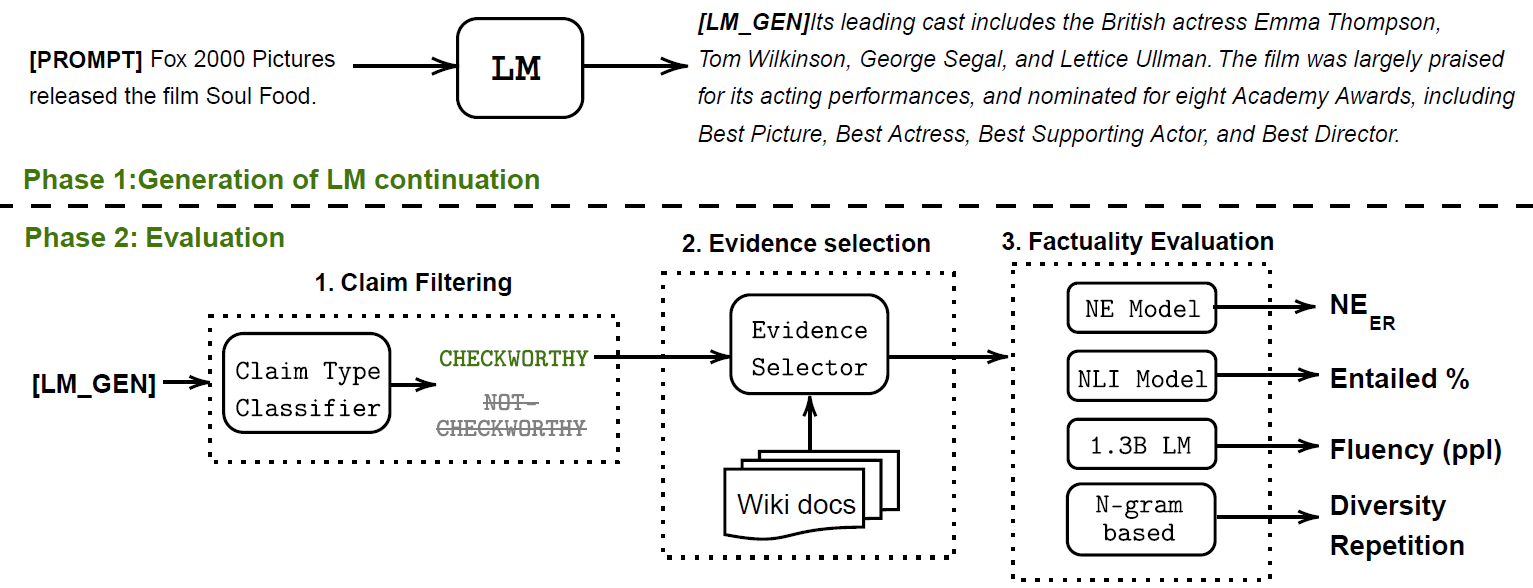
Pretrained language models (LMs) are susceptible to generate text with nonfactual information. In this work, we measure and improve the factual accuracy of large-scale LMs for open-ended text generation. We design the FactualityPrompts test set and metrics to measure the factuality of LM generations. Based on that, we study the factual accuracy of LMs with parameter sizes ranging from 126M to 530B. Interestingly, we find that larger LMs are more factual than smaller ones, although a previous study suggests that larger LMs can be less truthful in terms of misconceptions. In addition, popular sampling algorithms (e.g., top-p) in open-ended text generation can harm the factuality due to the "uniform randomness" introduced at every sampling step. We propose the factual-nucleus sampling algorithm that dynamically adapts the randomness to improve the factuality of generation while maintaining quality. Furthermore, we analyze the inefficiencies of the standard training method in learning correct associations between entities from factual text corpus (e.g., Wikipedia). We propose a factuality-enhanced training method that uses TopicPrefix for better awareness of facts and sentence completion as the training objective, which can vastly reduce the factual errors.
翻译:未经培训的语言模型(LMS) 容易生成非事实信息的文本。 在这项工作中,我们测量并改进用于开放式文本生成的大型LMS的准确性。 我们设计了用于衡量LM世代真实性的“事实质量”测试套件和衡量标准。 在此基础上,我们研究参数大小从126M到530B的LMS的实际准确性。 有趣的是,我们发现,较大的LMS比较小的LM更符合事实,尽管先前的一项研究表明,较大的LMs在错误概念方面可能不那么真实。 此外,在开放式文本生成中,大众抽样算法(例如顶级p)会由于在每一个取样步骤中引入的“统一随机性”而损害事实质量。 我们建议采用事实核心抽样算法,动态地调整随机性,以提高一代的真实质量。 此外,我们分析了标准培训方法在学习实体之间从事实文本集(例如维基百科)获得正确联系方面的低效率。我们提议采用事实质量强化的培训方法,以降低客观认识度,以图式形式改进完成情况。