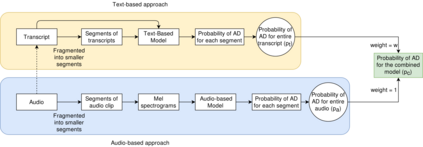
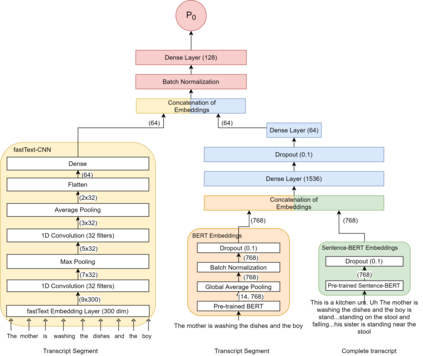
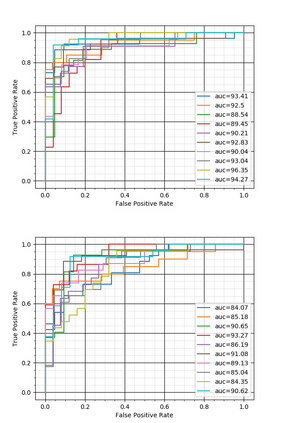
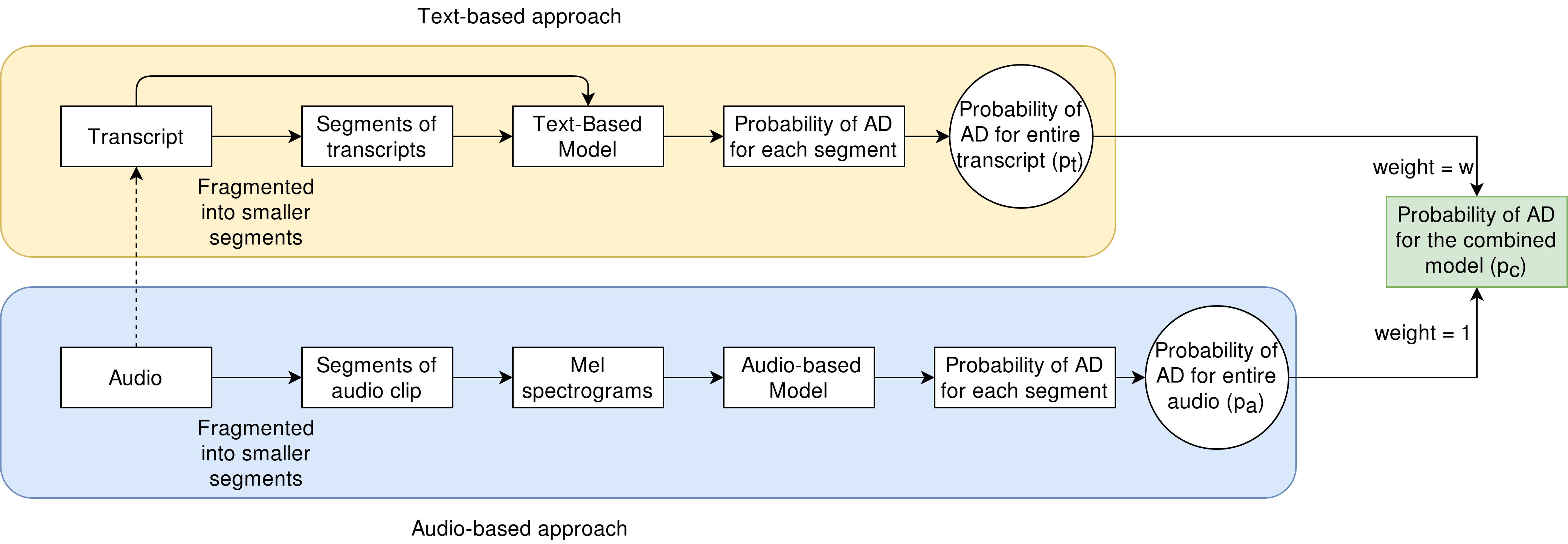
Reliable detection of the prodromal stages of Alzheimer's disease (AD) remains difficult even today because, unlike other neurocognitive impairments, there is no definitive diagnosis of AD in vivo. In this context, existing research has shown that patients often develop language impairment even in mild AD conditions. We propose a multimodal deep learning method that utilizes speech and the corresponding transcript simultaneously to detect AD. For audio signals, the proposed audio-based network, a convolutional neural network (CNN) based model, predicts the diagnosis for multiple speech segments, which are combined for the final prediction. Similarly, we use contextual embedding extracted from BERT concatenated with a CNN-generated embedding for classifying the transcript. The individual predictions of the two models are then combined to make the final classification. We also perform experiments to analyze the model performance when Automated Speech Recognition (ASR) system generated transcripts are used instead of manual transcription in the text-based model. The proposed method achieves 85.3% 10-fold cross-validation accuracy when trained and evaluated on the Dementiabank Pitt corpus.
翻译:与其它神经认知缺陷不同的是,目前对阿尔茨海默氏病(AD)的发病阶段仍难以可靠地检测,因为与其他神经认知缺陷不同,对AD在体内没有确切的诊断。在这方面,现有研究表明,病人甚至在轻微的AD条件下也往往会发展语言障碍。我们建议采用多式深层次学习方法,同时使用语言和相应的笔录来检测AD。对于音频信号,拟议的音频网络,即基于神经网络的模式,预测了多种语言部分的诊断,这些部分是最终预测的结合。同样,我们使用从BERT中提取的与CNN生成的笔录合并的上环境嵌入,然后将两种模式的个别预测合并起来进行最后分类。我们还进行实验,在使用自动语音识别系统生成的笔录时,而不是在基于文本的模型中使用人工抄录时,分析模型的性能。拟议方法在对Dementiabank Pitampion进行训练和评价时,达到85.3% 10倍的交叉校验准确度。