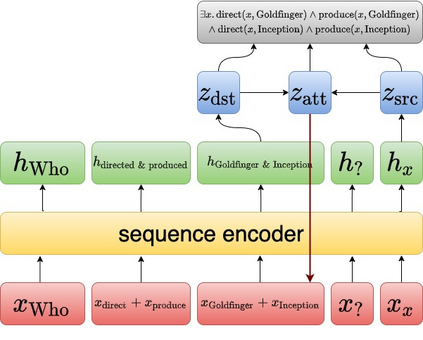
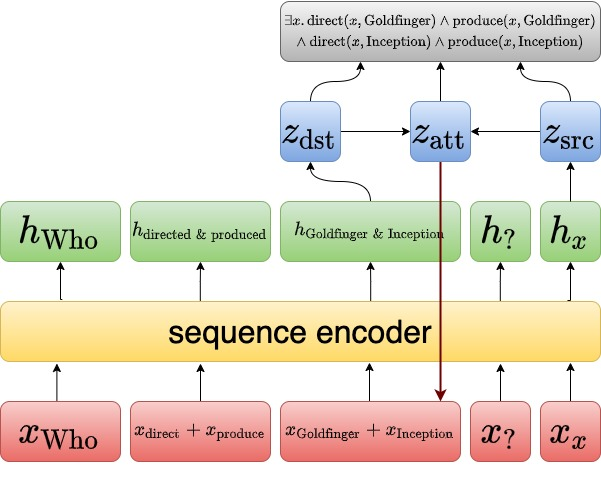
Question answering models struggle to generalize to novel compositions of training patterns, such to longer sequences or more complex test structures. Current end-to-end models learn a flat input embedding which can lose input syntax context. Prior approaches improve generalization by learning permutation invariant models, but these methods do not scale to more complex train-test splits. We propose Grounded Graph Decoding, a method to improve compositional generalization of language representations by grounding structured predictions with an attention mechanism. Grounding enables the model to retain syntax information from the input in thereby significantly improving generalization over complex inputs. By predicting a structured graph containing conjunctions of query clauses, we learn a group invariant representation without making assumptions on the target domain. Our model significantly outperforms state-of-the-art baselines on the Compositional Freebase Questions (CFQ) dataset, a challenging benchmark for compositional generalization in question answering. Moreover, we effectively solve the MCD1 split with 98% accuracy.
翻译:问题解答模型试图概括培训模式的新构成, 诸如较长的序列或更复杂的测试结构。 当前端到端模型学会一个平坦的输入嵌入, 可能会失去输入语法背景。 先前的方法通过学习变异模型来改进一般化, 但是这些方法没有规模到更复杂的火车测试分解。 我们提出基底图分解方法, 一种通过关注机制对结构化预测进行基础化预测来改进语言代表的构成概括化的方法。 基底图使模型能够保留输入的语法信息, 从而大大改进对复杂输入的概括化。 通过预测含有查询条款组合的结构化图表, 我们学习了一个不假设目标域的变异代表群体。 我们的模型大大超越了关于构成自由基础问题( CFQ) 数据集的最新基线, 是一个具有挑战性的相关解析通用基准。 此外, 我们用98%的精确度有效地解析了 MCD1 。