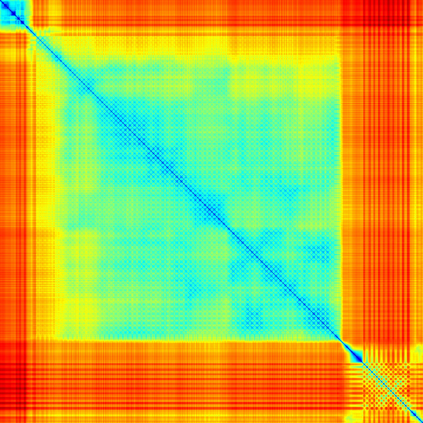
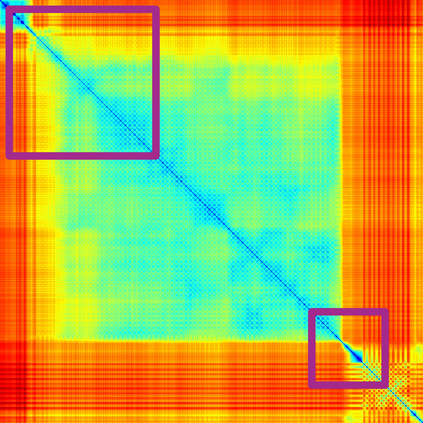
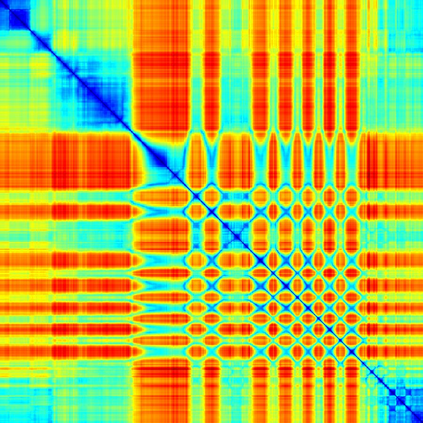
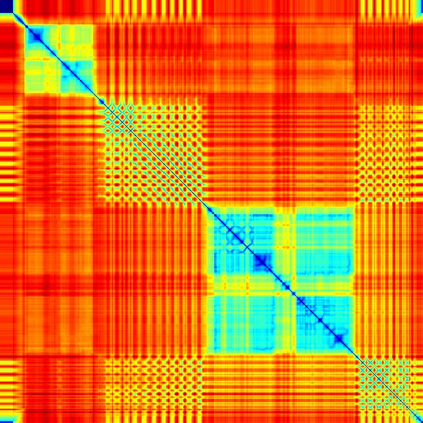
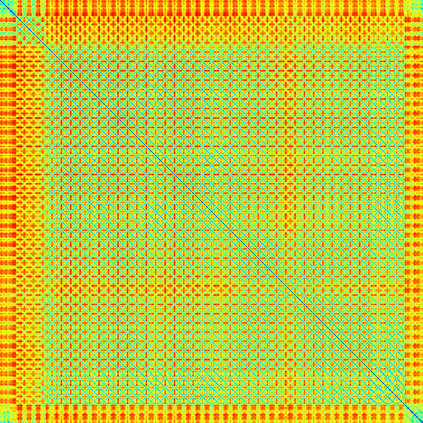
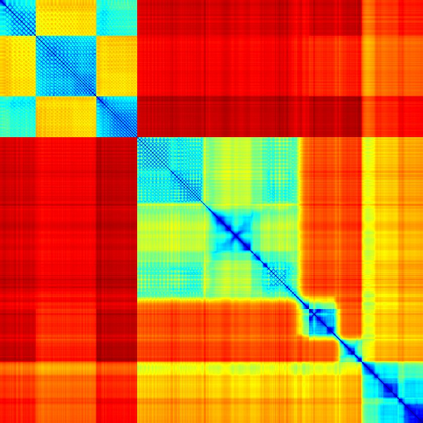
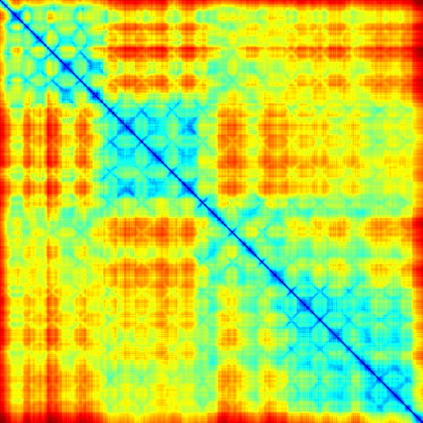
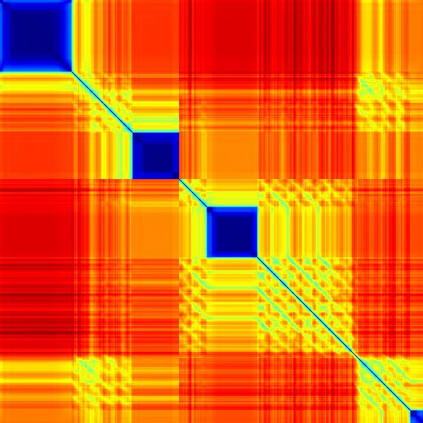
We address the problem of temporal localization of repetitive activities in a video, i.e., the problem of identifying all segments of a video that contain some sort of repetitive or periodic motion. To do so, the proposed method represents a video by the matrix of pairwise frame distances. These distances are computed on frame representations obtained with a convolutional neural network. On top of this representation, we design, implement and evaluate ReActNet, a lightweight convolutional neural network that classifies a given frame as belonging (or not) to a repetitive video segment. An important property of the employed representation is that it can handle repetitive segments of arbitrary number and duration. Furthermore, the proposed training process requires a relatively small number of annotated videos. Our method raises several of the limiting assumptions of existing approaches regarding the contents of the video and the types of the observed repetitive activities. Experimental results on recent, publicly available datasets validate our design choices, verify the generalization potential of ReActNet and demonstrate its superior performance in comparison to the current state of the art.
翻译:我们用视频解决重复活动的时间定位问题,即确定含有某种重复或周期性动作的视频的所有部分的问题。为此,拟议方法代表了双向框架距离矩阵的视频。这些距离是在与一个神经网络一起获得的框架表达式上计算的。除了这一表述式外,我们设计、实施和评估了ReActNet,这是一个轻量级的神经神经网络,将一个特定框架归类为属于(或不属于)重复视频部分。雇用代表的一个重要属性是它能够处理任意数量和持续时间的重复部分。此外,拟议培训过程需要数量相对较少的附加说明的视频。我们的方法提出了一些关于视频内容和所观察到的重复活动类型的现有做法的限制性假设。最近公开提供的数据集的实验结果证实了我们的设计选择,核查了ReActNet的总体潜力,并表明它相对于目前艺术状况的优异性表现。