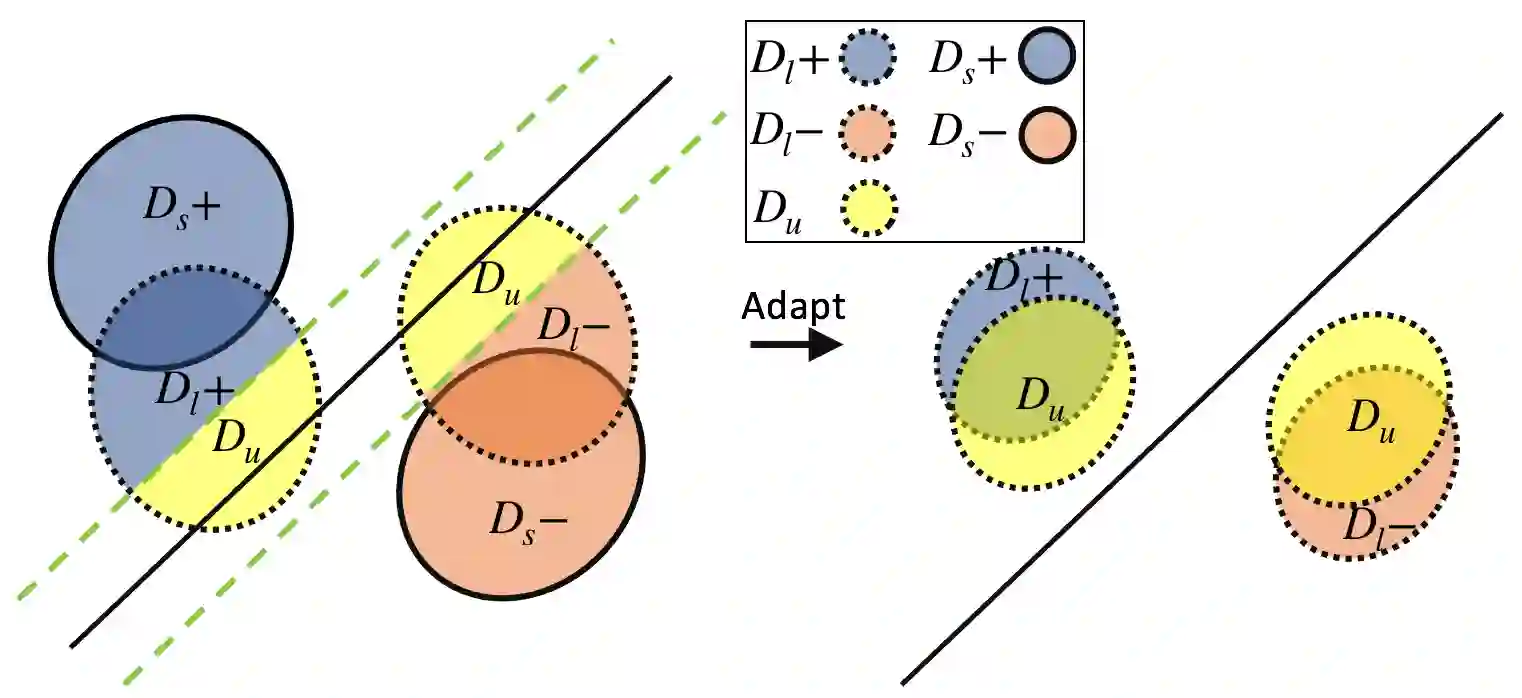
Due to privacy, storage, and other constraints, there is a growing need for unsupervised domain adaptation techniques in machine learning that do not require access to the data used to train a collection of source models. Existing methods for such multi-source-free domain adaptation typically train a target model using supervised techniques in conjunction with pseudo-labels for the target data, which are produced by the available source models. However, we show that assigning pseudo-labels to only a subset of the target data leads to improved performance. In particular, we develop an information-theoretic bound on the generalization error of the resulting target model that demonstrates an inherent bias-variance trade-off controlled by the subset choice. Guided by this analysis, we develop a method that partitions the target data into pseudo-labeled and unlabeled subsets to balance the trade-off. In addition to exploiting the pseudo-labeled subset, our algorithm further leverages the information in the unlabeled subset via a traditional unsupervised domain adaptation feature alignment procedure. Experiments on multiple benchmark datasets demonstrate the superior performance of the proposed method.
翻译:由于隐私、储存和其他限制,在机器学习中日益需要不受监督的域适应技术,这些技术不需要获得用于培训源模型收集的数据。这种多源域适应的现有方法通常在利用现有源模型制作的目标数据伪标签的同时,使用监督技术来培训一个目标模型。然而,我们显示,将伪标签仅仅分配给目标数据的一个子集,可以提高性能。特别是,我们开发了一个信息理论约束,将由此产生的目标模型的概括性错误作为信息约束,显示子集选择所控制的内在偏差交易。我们以这一分析为指导,开发了一种方法,将目标数据分成假标签和无标签的子集,以平衡交易。除了利用伪标签子集外,我们的算法还通过传统的未经监督的域适应特征调整程序,进一步利用未标子集中的信息。关于多个基准数据集的实验显示了拟议方法的优异性。