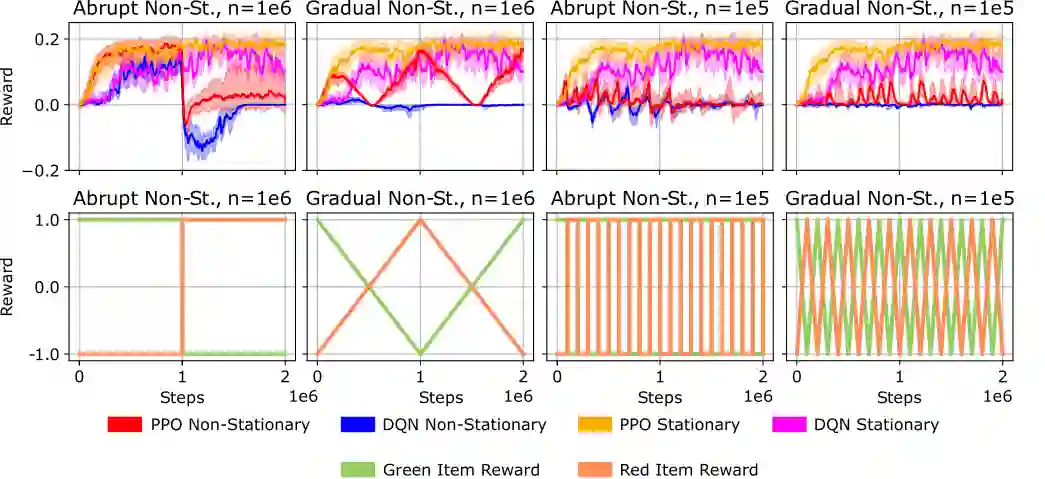
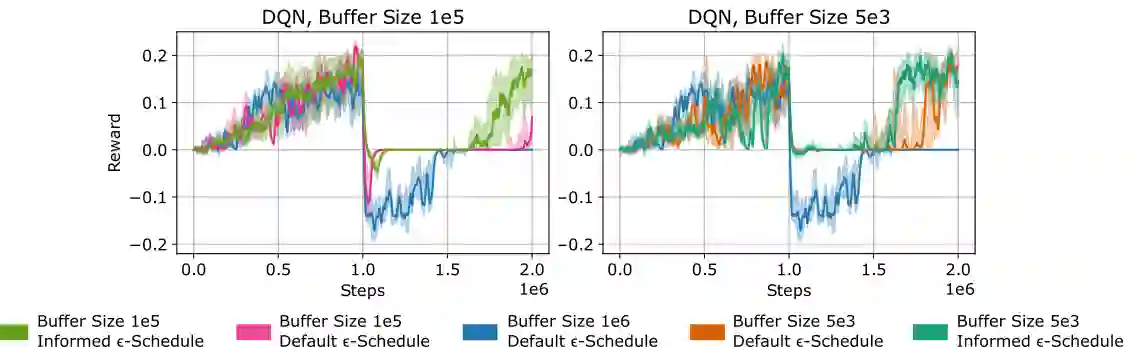
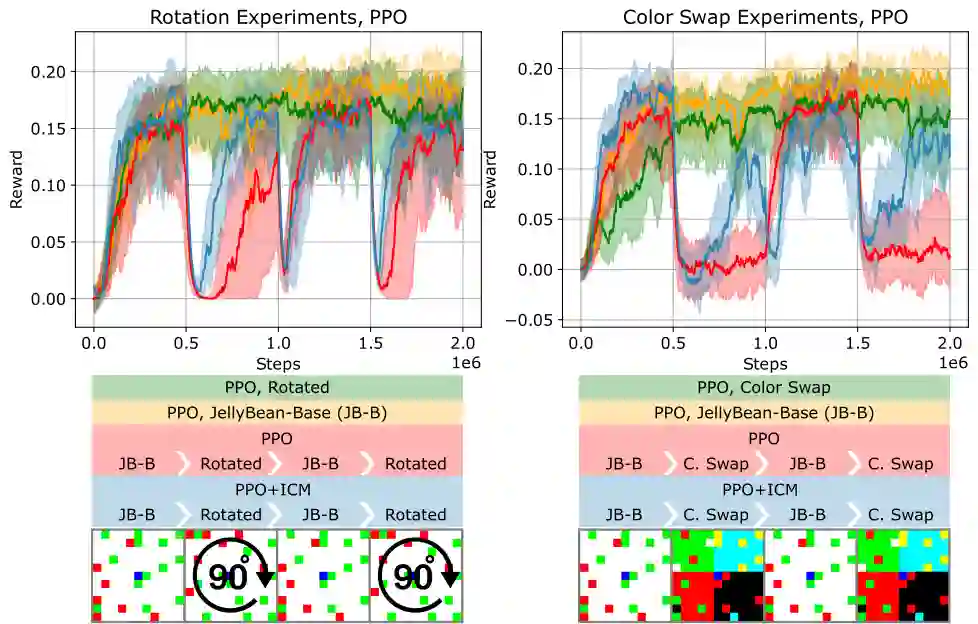
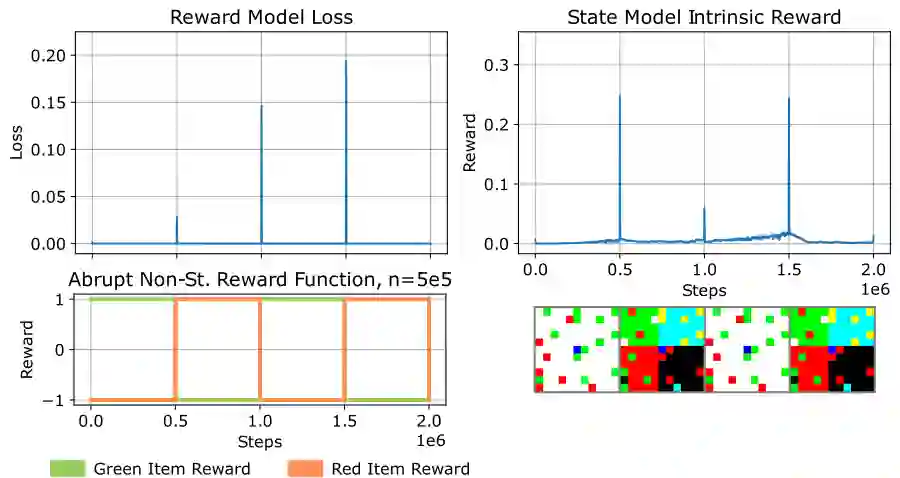
In lifelong learning, an agent learns throughout its entire life without resets, in a constantly changing environment, as we humans do. Consequently, lifelong learning comes with a plethora of research problems such as continual domain shifts, which result in non-stationary rewards and environment dynamics. These non-stationarities are difficult to detect and cope with due to their continuous nature. Therefore, exploration strategies and learning methods are required that are capable of tracking the steady domain shifts, and adapting to them. We propose Reactive Exploration to track and react to continual domain shifts in lifelong reinforcement learning, and to update the policy correspondingly. To this end, we conduct experiments in order to investigate different exploration strategies. We empirically show that representatives of the policy-gradient family are better suited for lifelong learning, as they adapt more quickly to distribution shifts than Q-learning. Thereby, policy-gradient methods profit the most from Reactive Exploration and show good results in lifelong learning with continual domain shifts. Our code is available at: https://github.com/ml-jku/reactive-exploration.
翻译:在终身学习中,一个代理人在不断变化的环境中,像我们人类一样,在不断变化的环境中,在整个一生中学习,没有累赘。因此,终身学习伴随着大量研究问题,例如连续的域变,导致非静止的奖励和环境动态。这些非静止的事物由于具有连续性而难以发现和应付。因此,需要探索战略和学习方法,能够跟踪稳定的域变,并适应这些变化。我们提议进行 " 积极探索 ",跟踪和应对终身强化学习的连续域变换,并相应更新政策。我们为此进行实验,以调查不同的探索战略。我们从经验上表明,政策等级家庭的代表更适合终身学习,因为他们比Q学习更迅速地适应分布变换。因此,政策变迁方法最能从累进的域变换中获利,并在终身学习中不断的域变换出良好结果。我们的代码可以在https://github.com/ml-jku/reactive-exlocation上查到。