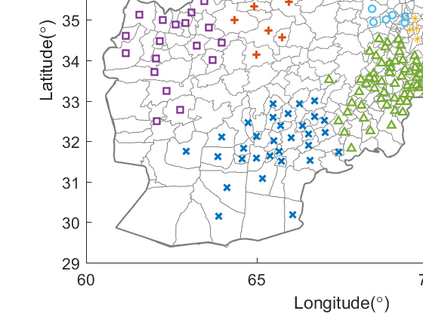
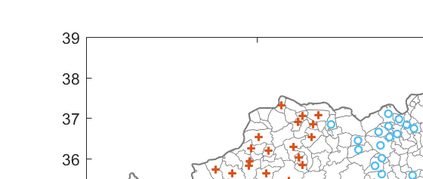
This paper presents and analyzes an approach to cluster-based inference for dependent data. The primary setting considered here is with spatially indexed data in which the dependence structure of observed random variables is characterized by a known, observed dissimilarity measure over spatial indices. Observations are partitioned into clusters with the use of an unsupervised clustering algorithm applied to the dissimilarity measure. Once the partition into clusters is learned, a cluster-based inference procedure is applied to a statistical hypothesis testing procedure. The procedure proposed in the paper allows the number of clusters to depend on the data, which gives researchers a principled method for choosing an appropriate clustering level. The paper gives conditions under which the proposed procedure asymptotically attains correct size. A simulation study shows that the proposed procedure attains near nominal size in finite samples in a variety of statistical testing problems with dependent data.
翻译:本文件介绍并分析了对依附数据进行基于集群的推断的方法。本文考虑的主要依据是空间指数数据,其中观察到的随机变量的依附性结构的特征是相对于空间指数的已知的、观测到的不同度量。观测被分成组群,采用适用于不同度量的未经监督的集群算法。一旦了解分解到集群,就对统计假设测试程序适用基于集群的推断程序。本文件中提议的程序允许根据数据来计算组群的数量,从而使研究人员能够有原则地选择适当的集群等级。该文件提供了条件,使拟议的程序在瞬间达到正确的尺寸。模拟研究表明,拟议的程序在与依赖数据有关的各种统计测试问题中,在有限的样本中达到了接近名义大小。