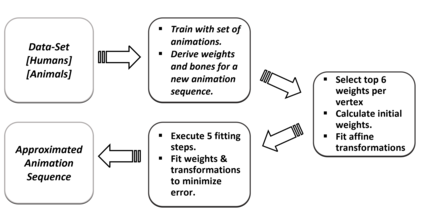
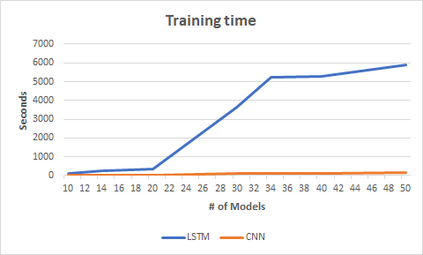
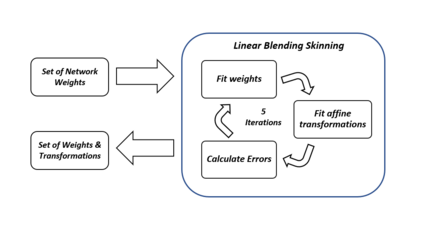
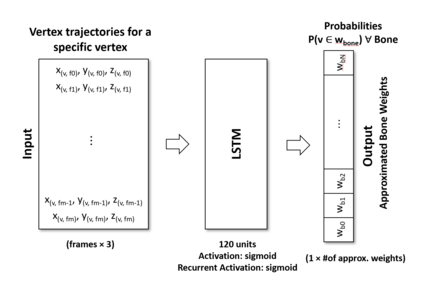
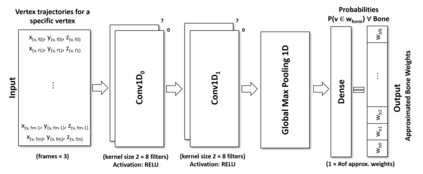
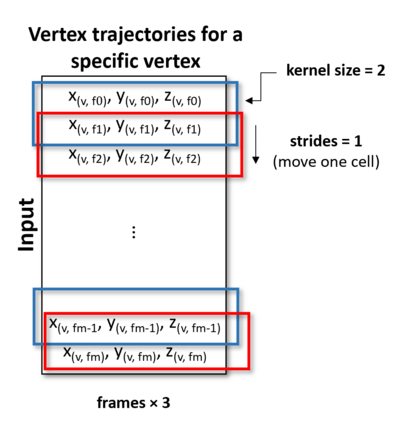
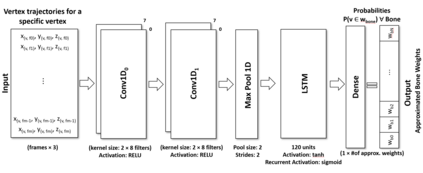
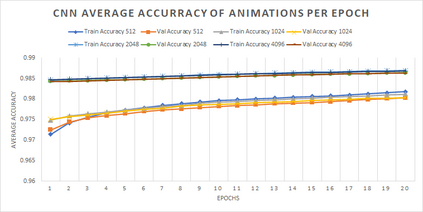
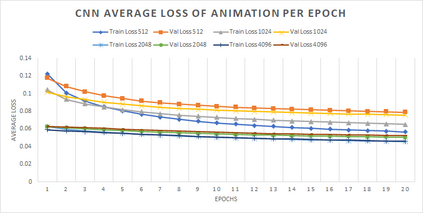
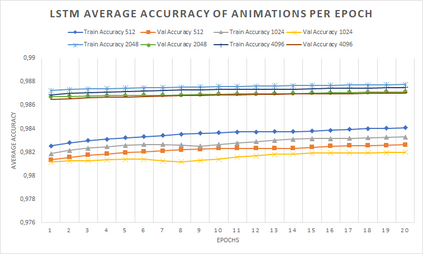
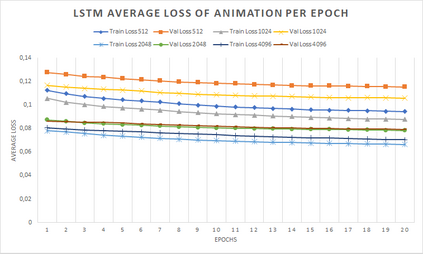
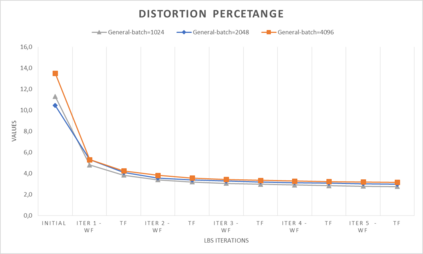
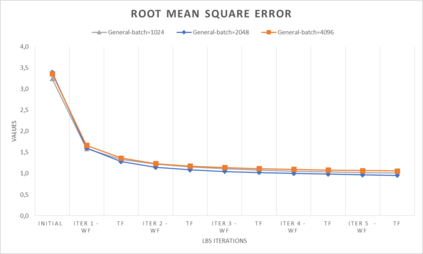
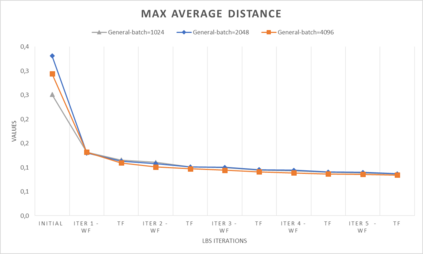
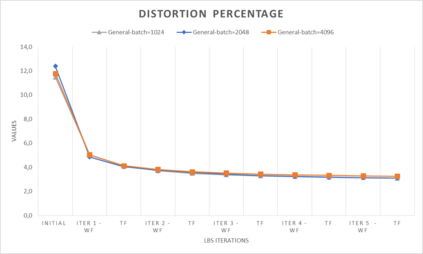
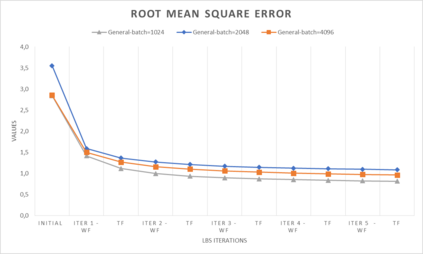
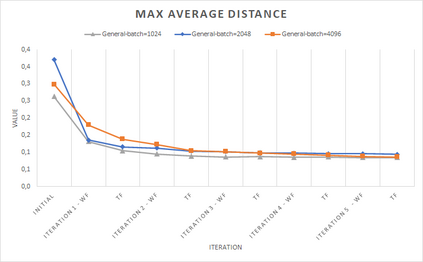
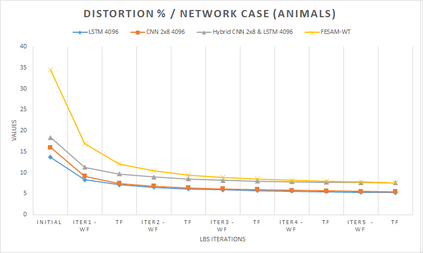
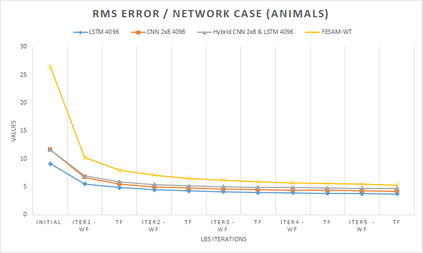
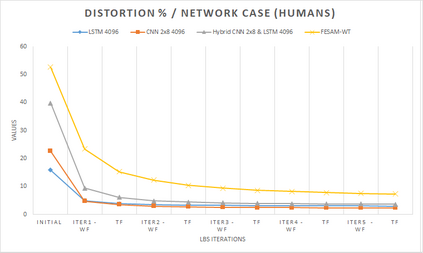
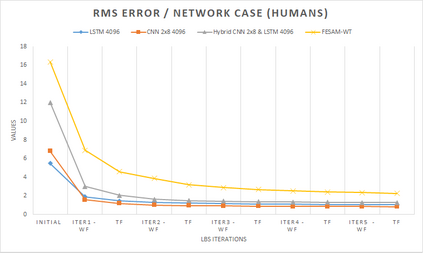
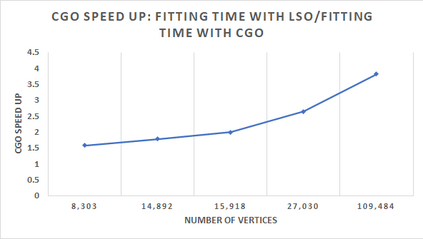
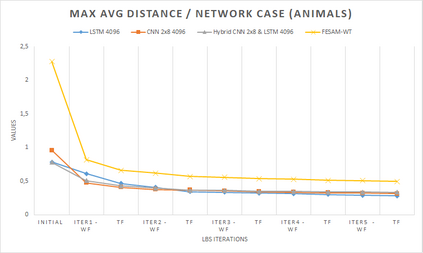
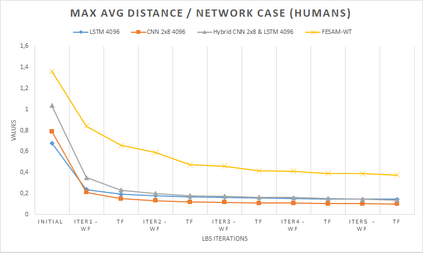
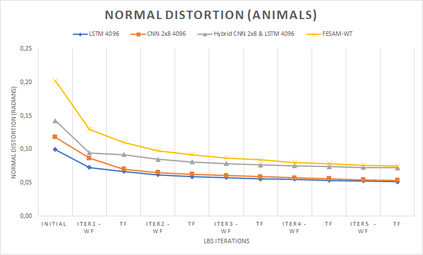
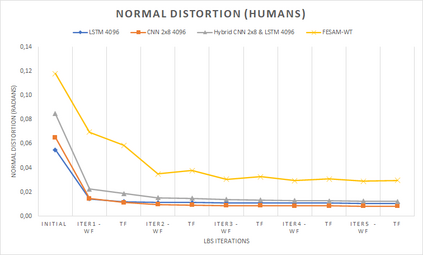
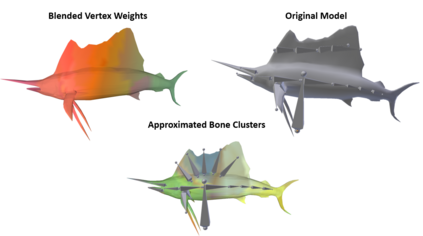
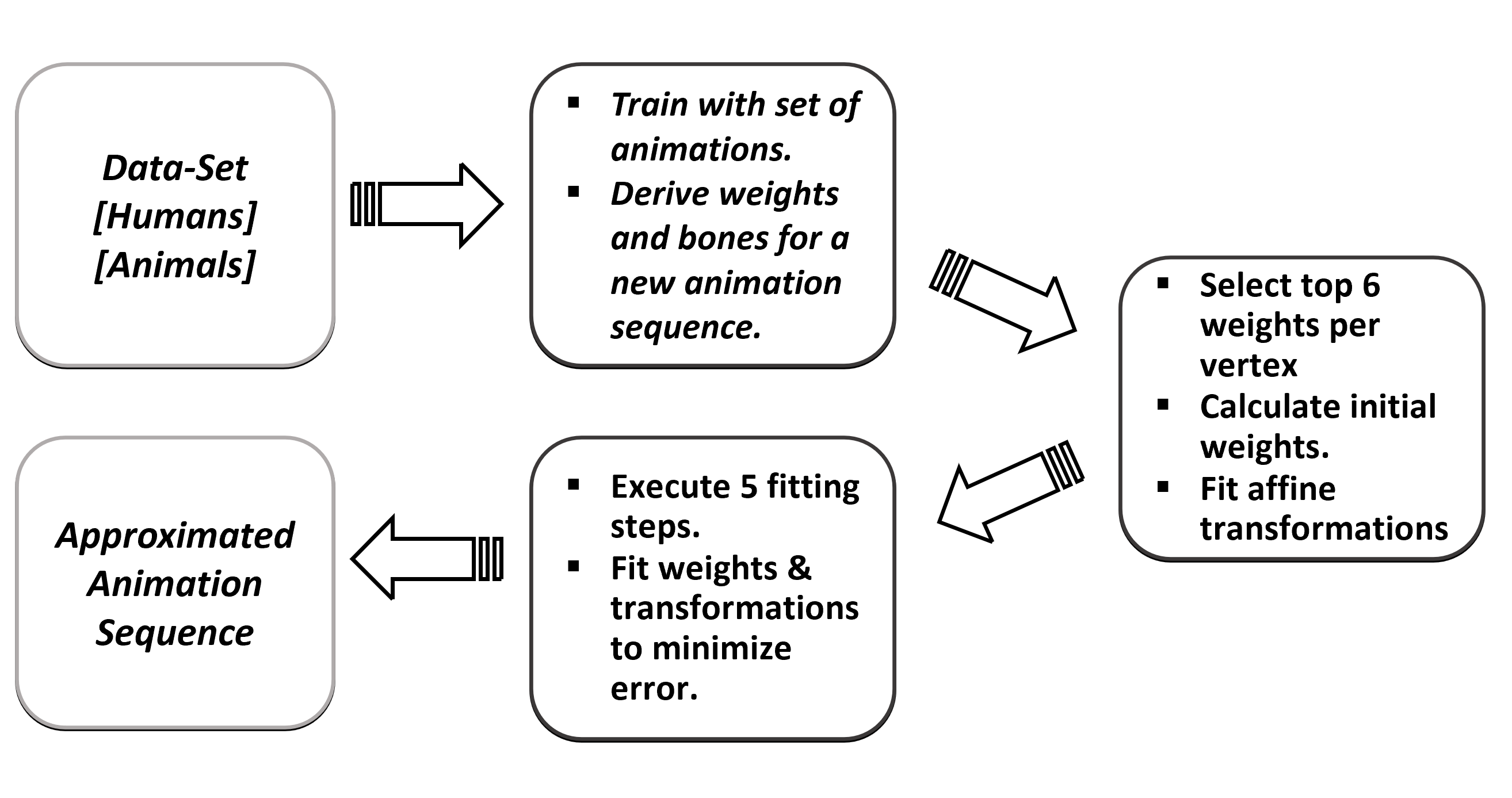
In computer graphics, animation compression is essential for efficient storage, streaming and reproduction of animated meshes. Previous work has presented efficient techniques for compression by deriving skinning transformations and weights using clustering of vertices based on geometric features of vertices over time. In this work we present a novel approach that assigns vertices to bone-influenced clusters and derives weights using deep learning through a training set that consists of pairs of vertex trajectories (temporal vertex sequences) and the corresponding weights drawn from fully rigged animated characters. The approximation error of the resulting linear blend skinning scheme is significantly lower than the error of competent previous methods by producing at the same time a minimal number of bones. Furthermore, the optimal set of transformation and vertices is derived in fewer iterations due to the better initial positioning in the multidimensional variable space. Our method requires no parameters to be determined or tuned by the user during the entire process of compressing a mesh animation sequence.
翻译:在计算机图形中,动画压缩是高效存储、流流和复制动动模模质所必不可少的。 先前的工作已经展示了高效压缩技术, 其方法是利用根据一段时间内脊椎的几何特征对脊椎进行组合, 得出皮肤变换和重量。 在这项工作中, 我们提出了一个新颖的方法, 将脊椎分配到受骨头影响的圆团中, 并通过一套由顶部轨迹( 瞬时的顶部序列) 和从完全操纵的动画字符中提取的相应重量组成的培训集进行深层学习, 从而获得重力。 由此产生的线性混合皮革计划的近似差大大低于以往适当方法的差错, 方法是同时生成最小数量的骨骼。 此外, 由于在多维变量空间中的初始定位较好, 最佳的变形和脊柱组合从较少的迭代中衍生出。 我们的方法不需要用户在组合组合动动画序列的整个过程中确定或调整参数。