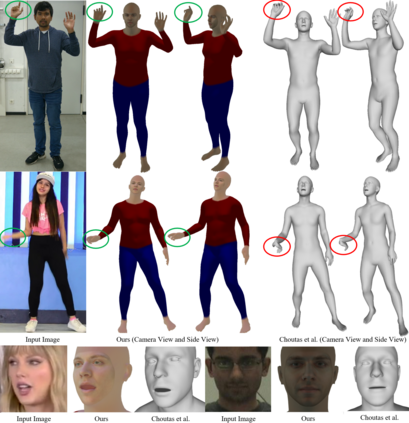
We present the first method for real-time full body capture that estimates shape and motion of body and hands together with a dynamic 3D face model from a single color image. Our approach uses a new neural network architecture that exploits correlations between body and hands at high computational efficiency. Unlike previous works, our approach is jointly trained on multiple datasets focusing on hand, body or face separately, without requiring data where all the parts are annotated at the same time, which is much more difficult to create at sufficient variety. The possibility of such multi-dataset training enables superior generalization ability. In contrast to earlier monocular full body methods, our approach captures more expressive 3D face geometry and color by estimating the shape, expression, albedo and illumination parameters of a statistical face model. Our method achieves competitive accuracy on public benchmarks, while being significantly faster and providing more complete face reconstructions.
翻译:我们提出了第一种实时全体捕获方法,该方法估算身体和手的形状和运动,同时使用一个单一颜色图像的动态 3D 脸模型。我们的方法使用一种新的神经网络结构,利用高计算效率的体与手之间的关联。与以往的工作不同,我们的方法在多数据集上共同培训,侧重于手上、身体上或面部,而不需要同时提供所有部分都附有注释的数据,而与此同时,这些数据在充分多样性下创造起来要困难得多。这种多数据集培训的可能性使得更能概括化。与早期的单体全体方法不同,我们的方法通过估计统计面模型的形状、表达、反照率和照明参数来捕捉到更直观的 3D 脸的几何和颜色。我们的方法在公共基准上实现了竞争性的准确性,同时大大加快并提供更完整的面部重建。