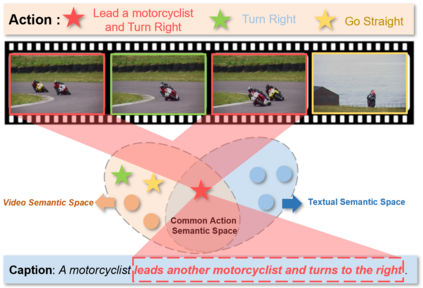
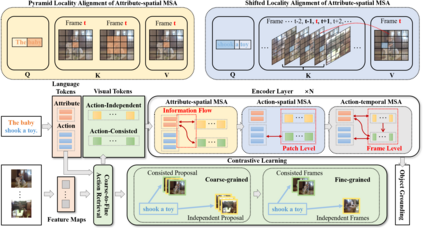
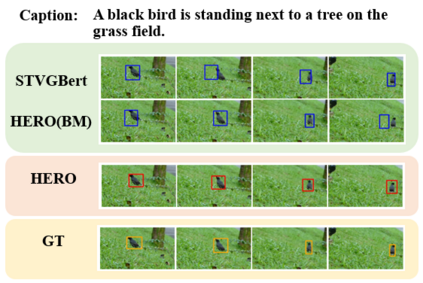
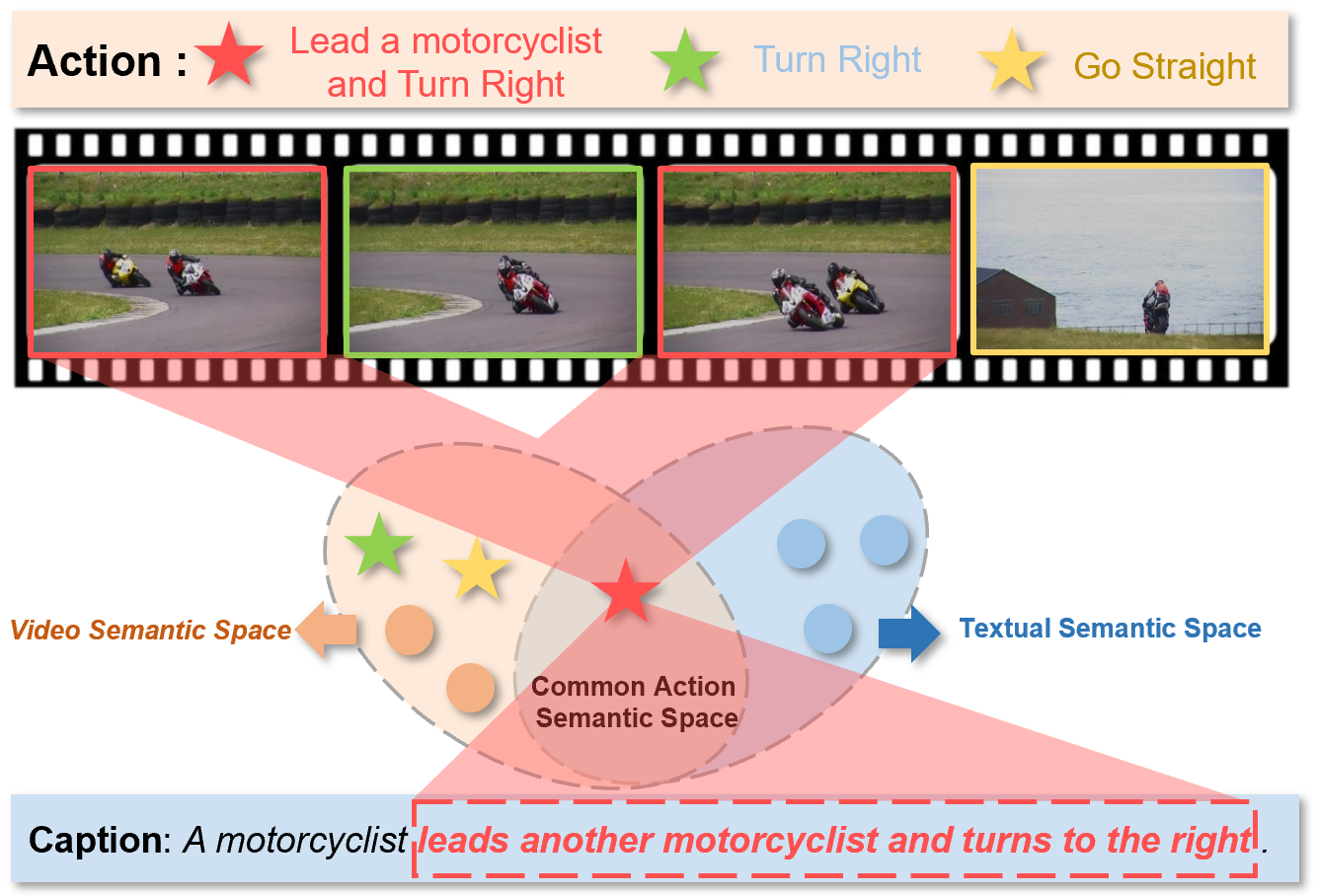
Video Object Grounding (VOG) is the problem of associating spatial object regions in the video to a descriptive natural language query. This is a challenging vision-language task that necessitates constructing the correct cross-modal correspondence and modeling the appropriate spatio-temporal context of the query video and caption, thereby localizing the specific objects accurately. In this paper, we tackle this task by a novel framework called HiErarchical spatio-tempoRal reasOning (HERO) with contrastive action correspondence. We study the VOG task at two aspects that prior works overlooked: (1) Contrastive Action Correspondence-aware Retrieval. Notice that the fine-grained video semantics (e.g., multiple actions) is not totally aligned with the annotated language query (e.g., single action), we first introduce the weakly-supervised contrastive learning that classifies the video as action-consistent and action-independent frames relying on the video-caption action semantic correspondence. Such a design can build the fine-grained cross-modal correspondence for more accurate subsequent VOG. (2) Hierarchical Spatio-temporal Modeling Improvement. While transformer-based VOG models present their potential in sequential modality (i.e., video and caption) modeling, existing evidence also indicates that the transformer suffers from the issue of the insensitive spatio-temporal locality. Motivated by that, we carefully design the hierarchical reasoning layers to decouple fully connected multi-head attention and remove the redundant interfering correlations. Furthermore, our proposed pyramid and shifted alignment mechanisms are effective to improve the cross-modal information utilization of neighborhood spatial regions and temporal frames. We conducted extensive experiments to show our HERO outperforms existing techniques by achieving significant improvement on two benchmark datasets.
翻译:视频目标定位( VOG) 是将视频中的空间物体区域与描述性自然语言查询联系起来的问题。 这是一个具有挑战性的视觉语言任务, 需要构建正确的跨模式通信, 并建模查询视频和字幕的适当时空空间环境, 从而精确地将特定对象本地化。 在本文中, 我们通过一个名为 HiArararchicic Statio- tempoRal Reaning (Hero) 的新框架来应对这项任务。 我们研究VOG任务, 其前两个方面曾被忽略:(1) 对抗性行动对应性对应性 Orver Retrievival。 提醒注意, 精细微的视频图像对称( e. g., 单项动作) 并不完全符合附加语言查询( ) 。 我们首先引入了一种薄弱的空间超强对比性学习, 将视频归为基于行动对立和行动对立的对立框架, 依靠视频对立式对立性通信。 这样的设计可以构建精细的图像对调的变压结构结构结构结构结构结构, 将我们现有的变更精确的变更精确的图像变更精确的变更变变的图像。