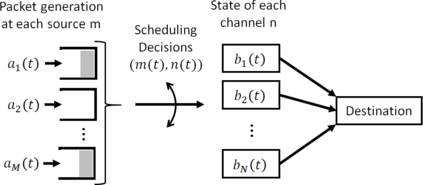
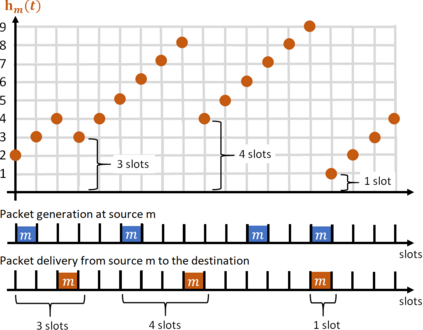
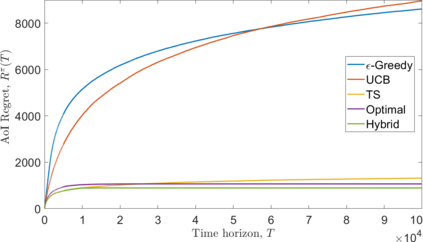
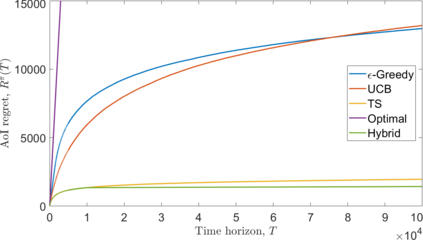
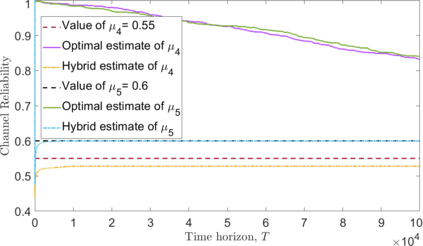
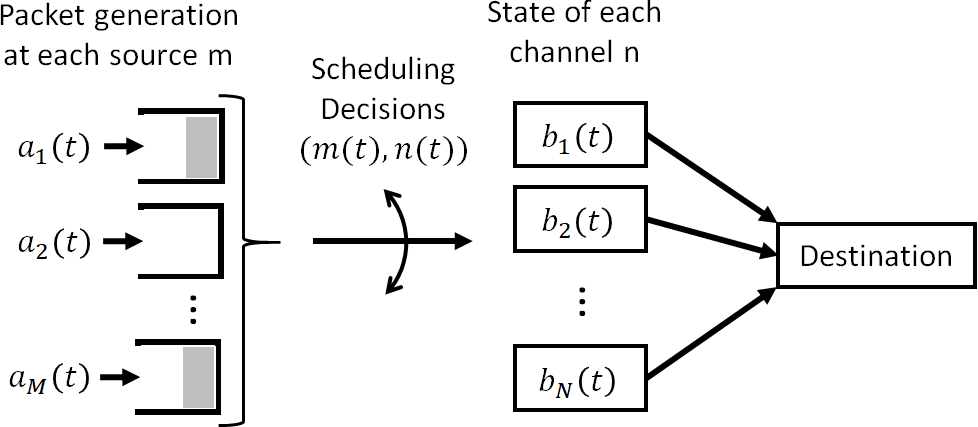
We consider a single-hop wireless network with sources transmitting time-sensitive information to the destination over multiple unreliable channels. Packets from each source are generated according to a stochastic process with known statistics and the state of each wireless channel (ON/OFF) varies according to a stochastic process with unknown statistics. The reliability of the wireless channels is to be learned through observation. At every time slot, the learning algorithm selects a single pair (source, channel) and the selected source attempts to transmit its packet via the selected channel. The probability of a successful transmission to the destination depends on the reliability of the selected channel. The goal of the learning algorithm is to minimize the Age-of-Information (AoI) in the network over $T$ time slots. To analyze the performance of the learning algorithm, we introduce the notion of AoI regret, which is the difference between the expected cumulative AoI of the learning algorithm under consideration and the expected cumulative AoI of a genie algorithm that knows the reliability of the channels a priori. The AoI regret captures the penalty incurred by having to learn the statistics of the channels over the $T$ time slots. The results are two-fold: first, we consider learning algorithms that employ well-known solutions to the stochastic multi-armed bandit problem (such as $\epsilon$-Greedy, Upper Confidence Bound, and Thompson Sampling) and show that their AoI regret scales as $\Theta(\log T)$; second, we develop a novel learning algorithm and show that it has $O(1)$ regret. To the best of our knowledge, this is the first learning algorithm with bounded AoI regret.
翻译:我们考虑的是单跳无线网络,其来源是通过多个不可靠的频道向目的地传输对时间敏感的信息。 每个来源的包包都是根据已知的统计数据和每个无线频道(ON/OFF)状况的随机分析程序产生的,根据无线频道(ON/OFF)的随机分析程序产生的。无线频道的可靠性是通过观察来学习的。学习算法在每一个时间段都选择了单一对(源、频道)和选定的源试图通过选定的频道传输其包。成功传输到目的地的概率取决于所选频道的可靠性。学习算法的目标是尽可能减少网络中超过$T的时间档的“信息时代”(AOI)的“信息时代”(AOI/OI)的状态。为了分析学习算法的性能,我们引入了“AoI”的概念,这就是所考虑的学习算法的预期累积AoI和预期的“AoI”之间的差别,而第二个知道频道的可靠性的基因算法是先入为先入为主的。我们先学习了“美元”的“数据”和“Tral”的“A”的“O-hroal-hisal 。我们学习了“O”的“O”的“O”的“O”的“结果,然后展示了“Oral-h”的“O”的“O”的“O-h”的“O”的“O”的“O”的“O-hol-t-tal-hol-hol-hol-hro-hol-hi 。