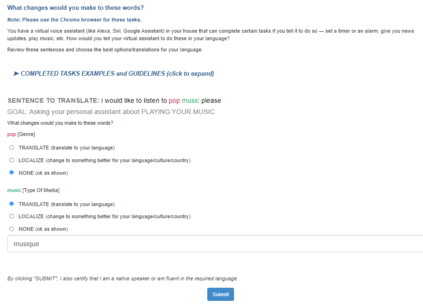
We present the MASSIVE dataset--Multilingual Amazon Slu resource package (SLURP) for Slot-filling, Intent classification, and Virtual assistant Evaluation. MASSIVE contains 1M realistic, parallel, labeled virtual assistant utterances spanning 51 languages, 18 domains, 60 intents, and 55 slots. MASSIVE was created by tasking professional translators to localize the English-only SLURP dataset into 50 typologically diverse languages from 29 genera. We also present modeling results on XLM-R and mT5, including exact match accuracy, intent classification accuracy, and slot-filling F1 score. We have released our dataset, modeling code, and models publicly.
翻译:我们提出了用于填空、意向分类和虚拟助理评价的多语言亚马逊 Slu 资源包(SLURP) 。 MASSIVE 包含 1M 现实、平行、贴标签的虚拟助理语句,涉及51种语言、18个领域、60个意图和55个空档。 任务化专业翻译将只有英语的 SLURP 数据集本地化,从29个基因组变为50种类型多样的语言。 我们还介绍了 XLM-R 和 mT5 的模型结果,包括精确匹配的准确性、意图分类准确性以及填空档F1 。 我们公布了我们的数据集、模型代码和模型。