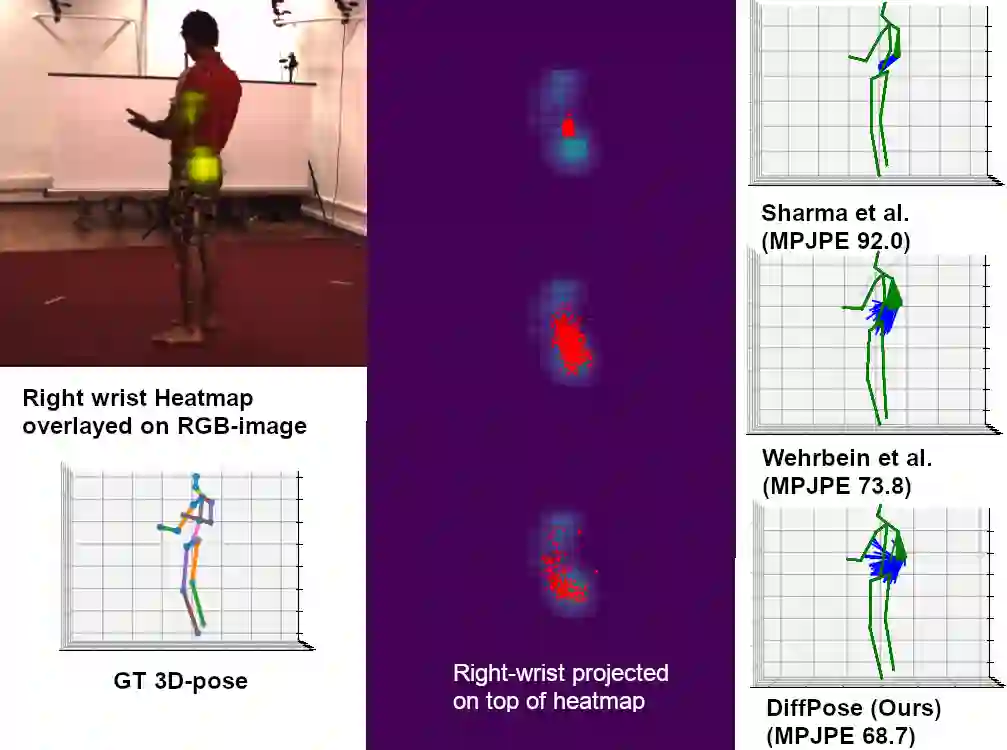
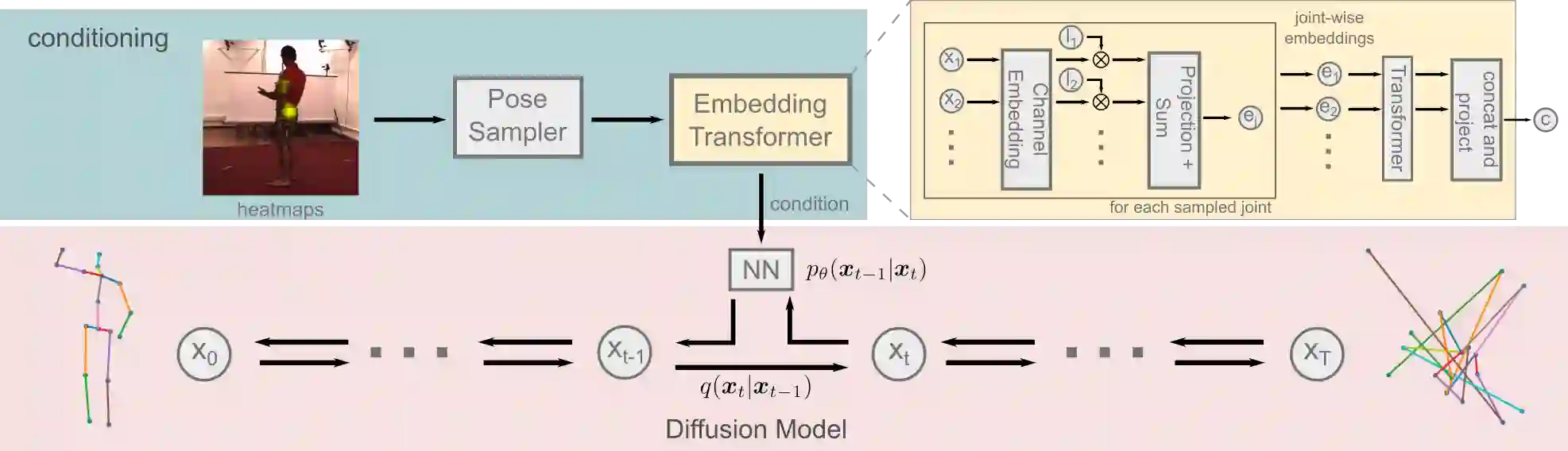
Traditionally, monocular 3D human pose estimation employs a machine learning model to predict the most likely 3D pose for a given input image. However, a single image can be highly ambiguous and induces multiple plausible solutions for the 2D-3D lifting step which results in overly confident 3D pose predictors. To this end, we propose \emph{DiffPose}, a conditional diffusion model, that predicts multiple hypotheses for a given input image. In comparison to similar approaches, our diffusion model is straightforward and avoids intensive hyperparameter tuning, complex network structures, mode collapse, and unstable training. Moreover, we tackle a problem of the common two-step approach that first estimates a distribution of 2D joint locations via joint-wise heatmaps and consecutively approximates them based on first- or second-moment statistics. Since such a simplification of the heatmaps removes valid information about possibly correct, though labeled unlikely, joint locations, we propose to represent the heatmaps as a set of 2D joint candidate samples. To extract information about the original distribution from these samples we introduce our \emph{embedding transformer} that conditions the diffusion model. Experimentally, we show that DiffPose slightly improves upon the state of the art for multi-hypothesis pose estimation for simple poses and outperforms it by a large margin for highly ambiguous poses.
翻译:传统上,单体 3D 人类表面估计使用机器学习模型来预测特定输入图像最有可能的 3D 。 然而, 单一图像可能非常模糊, 并且为 2D-3D 升降步骤带来多种可信的解决方案, 导致产生过于自信的 3D 显示预测值。 为此, 我们提议 emph{ DiffPose}, 一种有条件的传播模型, 用来预测特定输入图像的多重假设值。 与类似方法相比, 我们的传播模型是直截了当的, 避免了超光度调整、 复杂的网络结构、 模式崩溃和不稳定的培训。 此外, 我们处理了一个共同的两步法问题, 即首先通过联合的热映射仪来估计 2D 联合地点的分布, 并依次根据第一或第二步统计来估计 。 由于如此简化的热映射图, 我们建议将热映图作为一套 2D 联合候选样本的集。 为了从这些样本中提取原始分布的信息, 我们从这些样本中引入了 我们的 emph{ 模质变形模型, 并用简单的变形变形模型来展示 的模型的模型的模型, 演示的模型的模型, 展示的模型的模型的变形, 展示的模型的模型的模型, 的模型的模型的变形变形模型的变形, 展示的变形模型的变形, 展示的变形, 的变形的变形, 的变形的变形的模型的变形图的变形图的模型的变形图的模型的变形图。