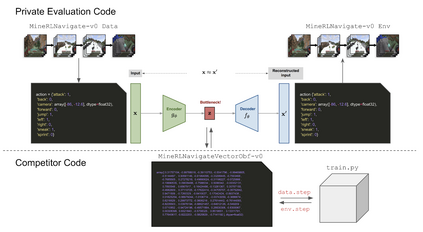
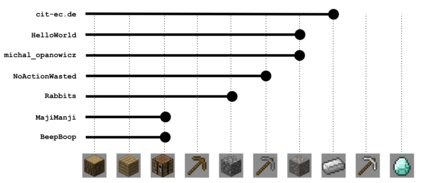
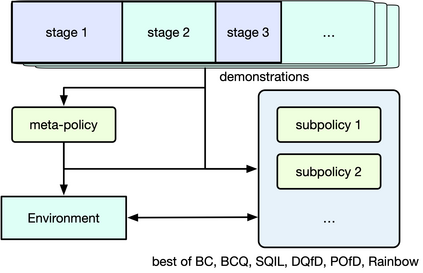
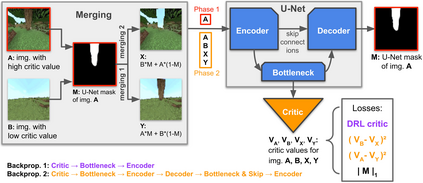
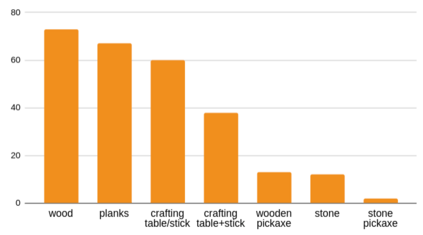
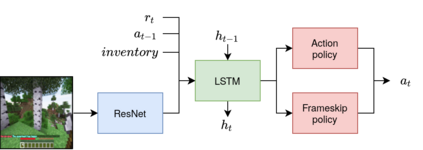
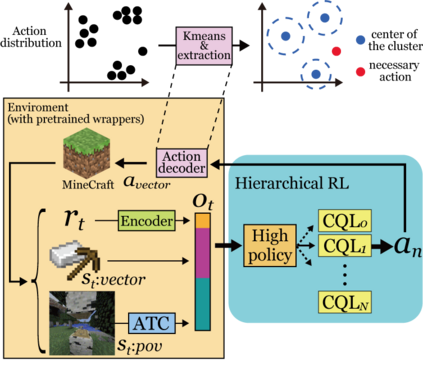
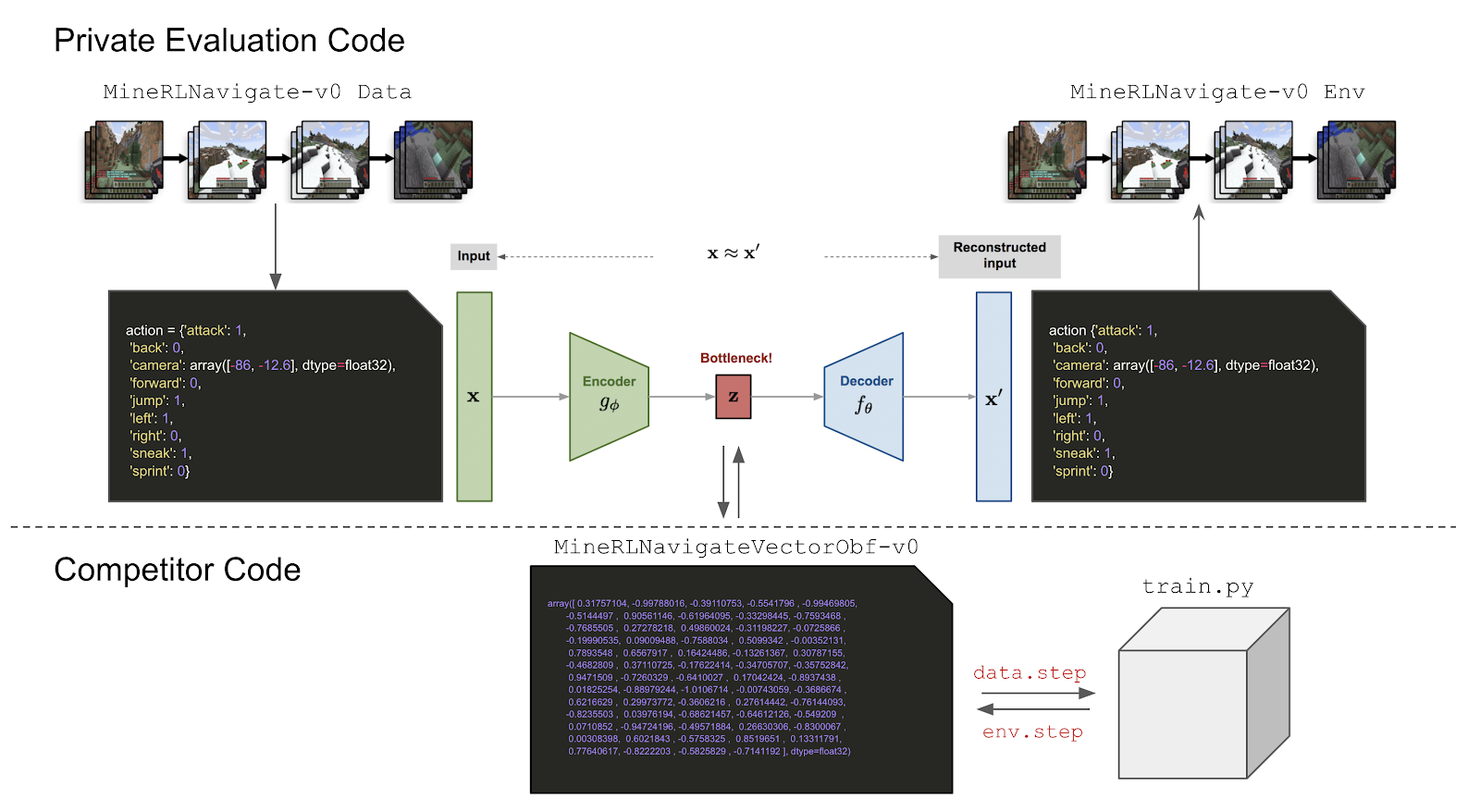
Reinforcement learning competitions have formed the basis for standard research benchmarks, galvanized advances in the state-of-the-art, and shaped the direction of the field. Despite this, a majority of challenges suffer from the same fundamental problems: participant solutions to the posed challenge are usually domain-specific, biased to maximally exploit compute resources, and not guaranteed to be reproducible. In this paper, we present a new framework of competition design that promotes the development of algorithms that overcome these barriers. We propose four central mechanisms for achieving this end: submission retraining, domain randomization, desemantization through domain obfuscation, and the limitation of competition compute and environment-sample budget. To demonstrate the efficacy of this design, we proposed, organized, and ran the MineRL 2020 Competition on Sample-Efficient Reinforcement Learning. In this work, we describe the organizational outcomes of the competition and show that the resulting participant submissions are reproducible, non-specific to the competition environment, and sample/resource efficient, despite the difficult competition task.
翻译:强化学习竞争已成为标准研究基准的基础,激发了最新技术的进步,并塑造了该领域的方向。尽管如此,大多数挑战都存在同样的根本性问题:参与者对挑战的解决方案通常是针对特定领域的,偏向于最大限度利用计算资源,不能保证可以复制。在本文件中,我们提出了一个新的竞争设计框架,促进制定克服这些障碍的算法。我们为此提出了四个核心机制:提交再培训、域随机化、通过域盘溶脱贫、限制竞争计算和环境抽样预算。为了展示这一设计的效率,我们提出、组织、组织并运行了《2020年地雷责任公约》关于抽样增强学习的竞争。在这项工作中,我们描述了竞争的组织结果,并表明,尽管竞争任务艰巨,但由此提交的参与者材料是可再生的、非竞争环境特有的、抽样/资源效率高的。