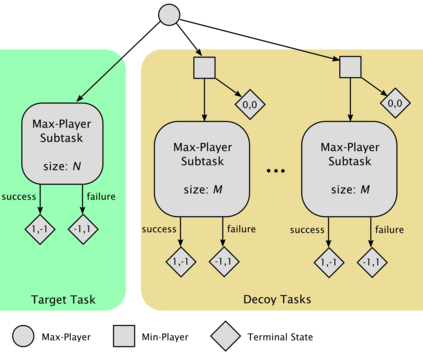
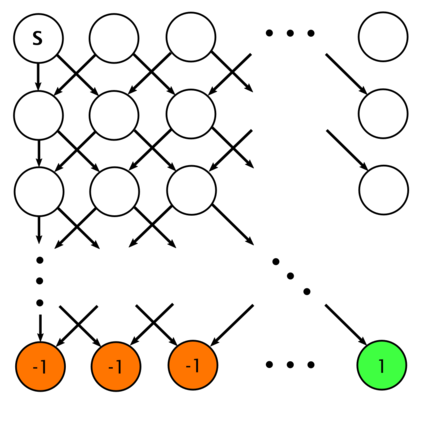
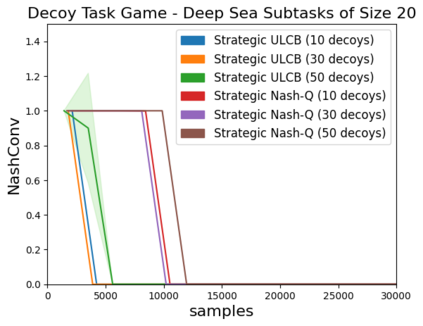
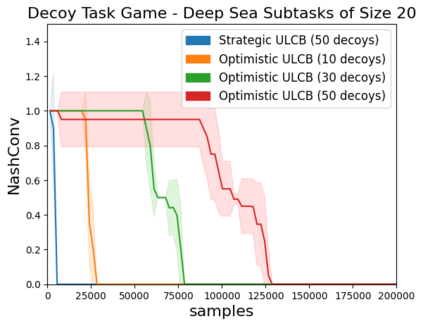
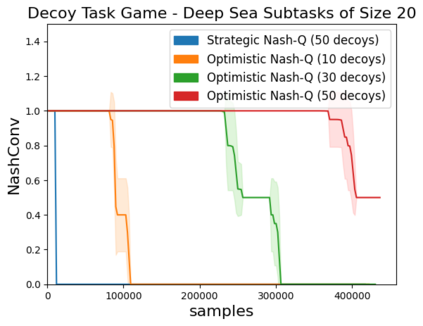
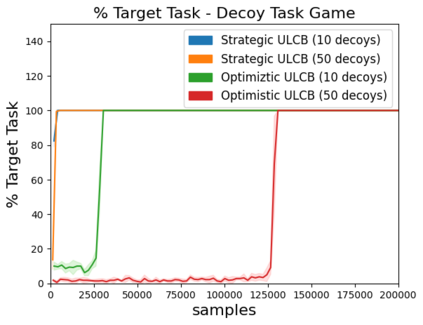
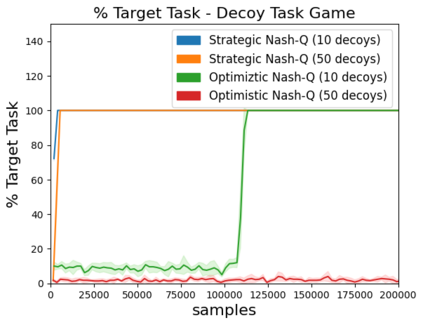
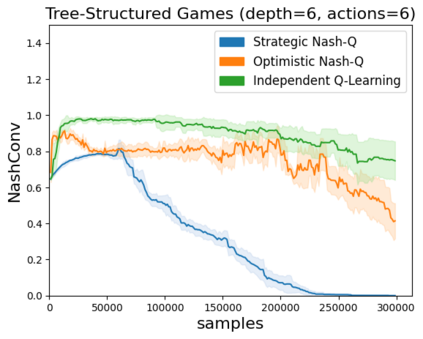
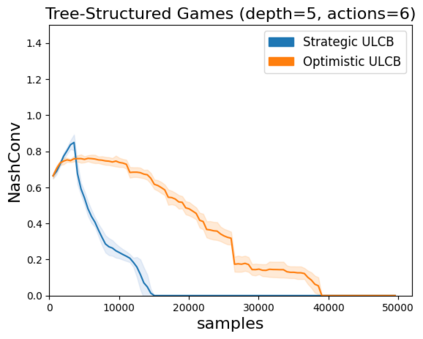
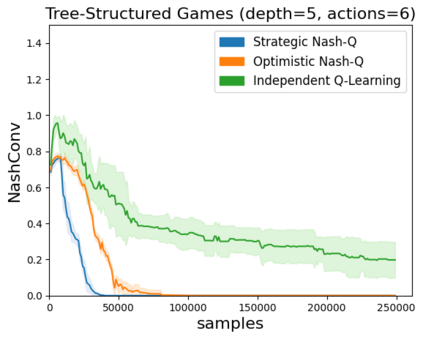
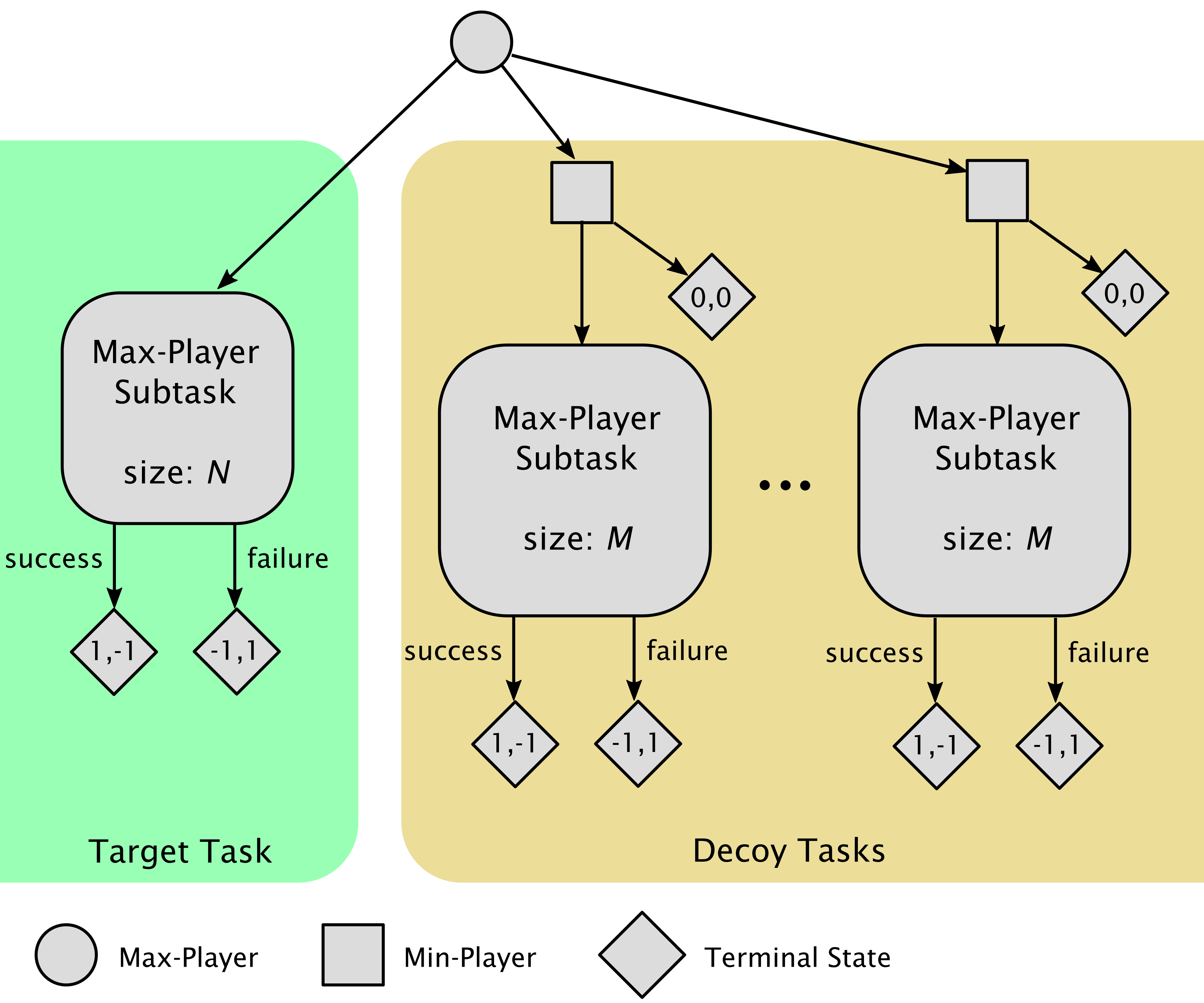
High sample complexity remains a barrier to the application of reinforcement learning (RL), particularly in multi-agent systems. A large body of work has demonstrated that exploration mechanisms based on the principle of optimism under uncertainty can significantly improve the sample efficiency of RL in single agent tasks. This work seeks to understand the role of optimistic exploration in non-cooperative multi-agent settings. We will show that, in zero-sum games, optimistic exploration can cause the learner to waste time sampling parts of the state space that are irrelevant to strategic play, as they can only be reached through cooperation between both players. To address this issue, we introduce a formal notion of strategically efficient exploration in Markov games, and use this to develop two strategically efficient learning algorithms for finite Markov games. We demonstrate that these methods can be significantly more sample efficient than their optimistic counterparts.
翻译:大量工作表明,基于不确定的乐观原则的勘探机制能够显著提高单一代理任务中RL的抽样效率。这项工作旨在了解乐观探索在不合作的多代理环境中的作用。我们将表明,在零和游戏中,乐观探索可导致学习者浪费与战略游戏无关的州空间的时间取样部分,因为只有通过双方合作才能达到。为了解决这一问题,我们引入了在Markov游戏中进行战略高效探索的正式概念,并利用这一正式概念为有限的Markov游戏开发两种战略高效学习算法。我们证明,这些方法的取样效率要比乐观对手高得多。