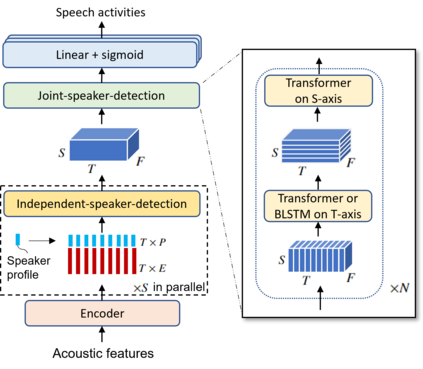
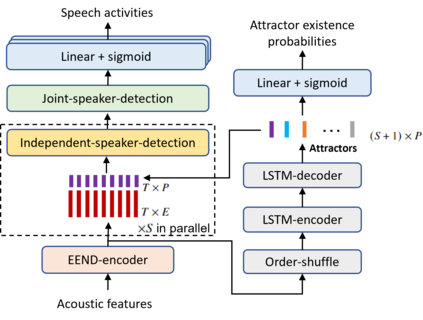
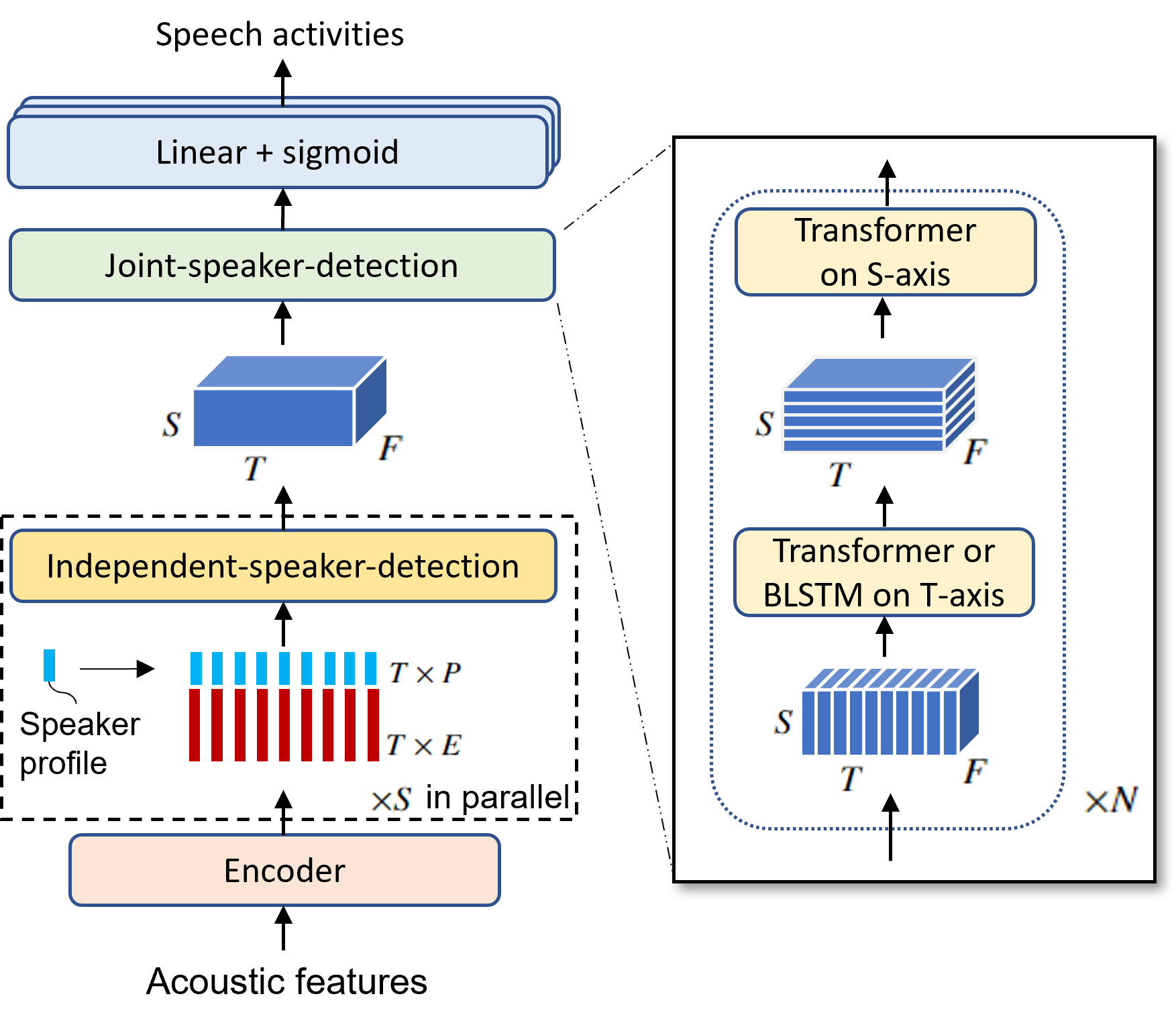
This paper describes a speaker diarization model based on target speaker voice activity detection (TS-VAD) using transformers. To overcome the original TS-VAD model's drawback of being unable to handle an arbitrary number of speakers, we investigate model architectures that use input tensors with variable-length time and speaker dimensions. Transformer layers are applied to the speaker axis to make the model output insensitive to the order of the speaker profiles provided to the TS-VAD model. Time-wise sequential layers are interspersed between these speaker-wise transformer layers to allow the temporal and cross-speaker correlations of the input speech signal to be captured. We also extend a diarization model based on end-to-end neural diarization with encoder-decoder based attractors (EEND-EDA) by replacing its dot-product-based speaker detection layer with the transformer-based TS-VAD. Experimental results on VoxConverse show that using the transformers for the cross-speaker modeling reduces the diarization error rate (DER) of TS-VAD by 11.3%, achieving a new state-of-the-art (SOTA) DER of 4.57%. Also, our extended EEND-EDA reduces DER by 6.9% on the CALLHOME dataset relative to the original EEND-EDA with a similar model size, achieving a new SOTA DER of 11.18% under a widely used training data setting.
翻译:本文描述以使用变压器的目标扬声器活动检测(TS-VAD)为基础的扩音器diarization模型。 为了克服最初的TS-VAD模型无法处理任意数目的发言者的缺点, 我们还调查了使用有不同长度时间和音量的输入电压的模型结构。 将变压层应用到扬声器轴中, 使模型输出与提供给TS- VAD模型的扬声器概况的顺序不敏感。 从时间角度的相继层在这些发声器变异器层之间相互穿插, 以便能够捕捉到输入语音信号信号信号的时空和跨声器的相互关系。 我们还将基于以电算器-变电解器吸引器(ENDU-EDA) 的顶端至端神经二分解模型(DUA-DER) 和 ENDU-DA 的 EDERA 的 EDU-DU A Unal- Develop AS 和 EDU-DA 的 EDU-DA 的EDA 和 AS-DU 的 RDU-DUA 的 RDA 的扩展 RA 的EDU-DA 的扩展 和 的 EDU-DU-DA 10 和 的 R 10 RA 的 RDU 的 R 的 R 10 和 的 R 的 R 和 的 R 的 R 的 RDU-DU 10 的 R 的 RDU 的 RDU 的 R 的 RDU 的 RDUDU 的 RDU 和 的 R 的 RDUDFA 和 的 R 的 R 的 R 的 R 的 R 的 R 的 R 和 和 的 R 的 R 和 和 的 R 的 R 的 RDUDUDU 的 RDUDUDFA 的 R 的 RDU 和 和 的 R 的 R 的 R 的 R 的 R 和 的 R 的 R 的 R 和 和 的 R 的 R 的 R 的 R 和 和