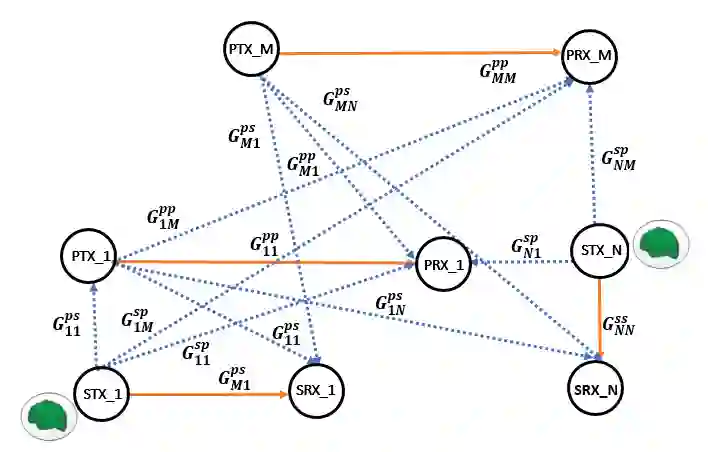
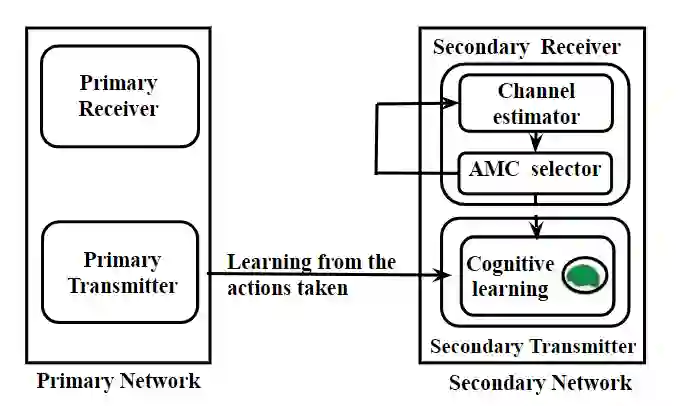
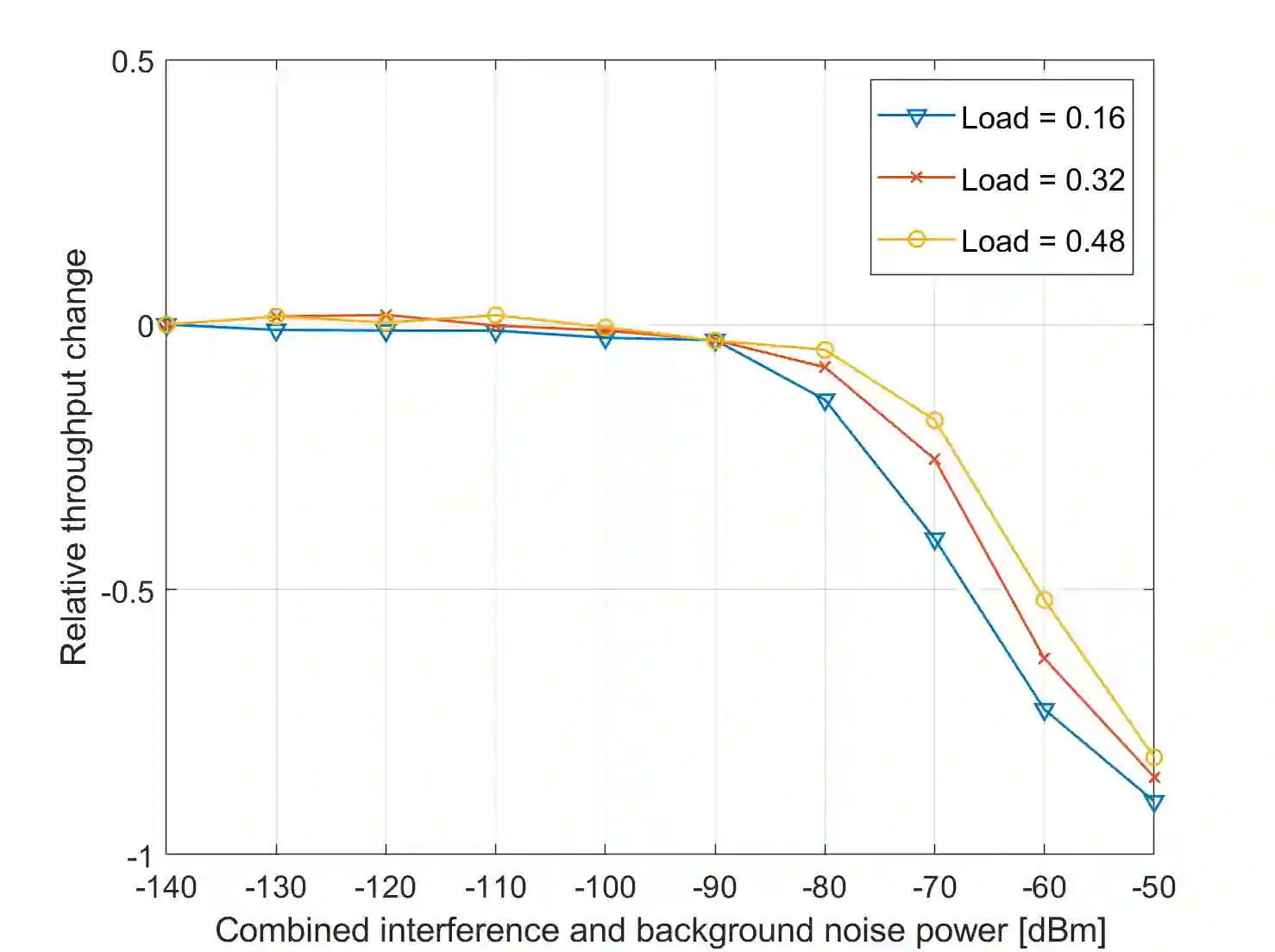
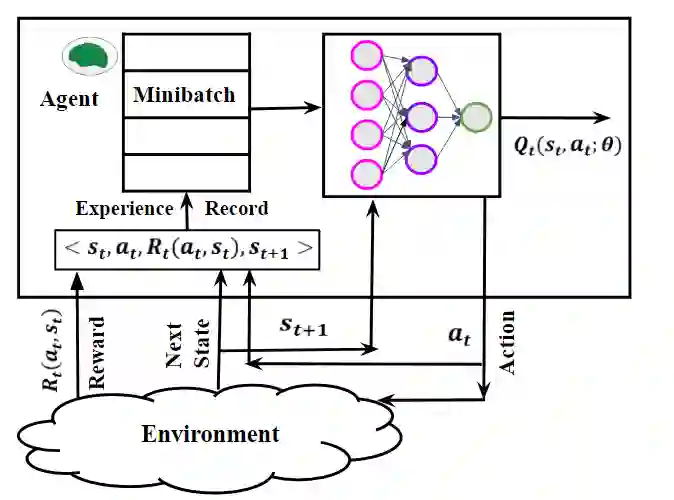
This paper presents a novel deep reinforcement learning-based resource allocation technique for the multi-agent environment presented by a cognitive radio network where the interactions of the agents during learning may lead to a non-stationary environment. The resource allocation technique presented in this work is distributed, not requiring coordination with other agents. It is shown by considering aspects specific to deep reinforcement learning that the presented algorithm converges in an arbitrarily long time to equilibrium policies in a non-stationary multi-agent environment that results from the uncoordinated dynamic interaction between radios through the shared wireless environment. Simulation results show that the presented technique achieves a faster learning performance compared to an equivalent table-based Q-learning algorithm and is able to find the optimal policy in 99% of cases for a sufficiently long learning time. In addition, simulations show that our DQL approach requires less than half the number of learning steps to achieve the same performance as an equivalent table-based implementation. Moreover, it is shown that the use of a standard single-agent deep reinforcement learning approach may not achieve convergence when used in an uncoordinated interacting multi-radio scenario
翻译:本文介绍了一个认知无线电网络为多试剂环境提出的一种新型的深入强化学习的资源分配技术,在这种环境中,代理人员在学习期间的互动可能导致非静止环境。这项工作中提出的资源分配技术是分布的,不需要与其他代理人员进行协调。通过考虑深强化学习的具体方面,可以表明,所介绍的算法在非静止多试剂环境中,在非静止多试剂环境中,由于无线电通过共享无线环境进行无线电之间不协调的动态互动而导致的平衡政策,在非静止多试剂环境中,在非经常性多试剂环境中,由于无线电通过共享无线环境,无线电台之间不协调的动态互动性互动性互动性互动性强化性学习方法,因此在非协调性多射线假设中使用的标准单剂深度强化性学习方法可能无法达到趋同。模拟表明,在不协调的多射线假设中使用的标准单剂强化性学习方法可能无法达到趋同性效果。