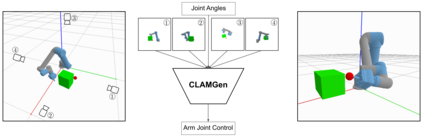
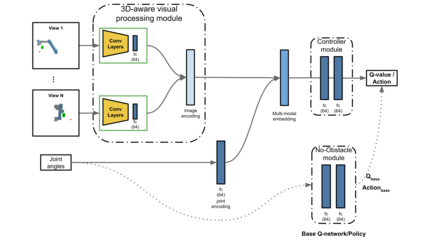
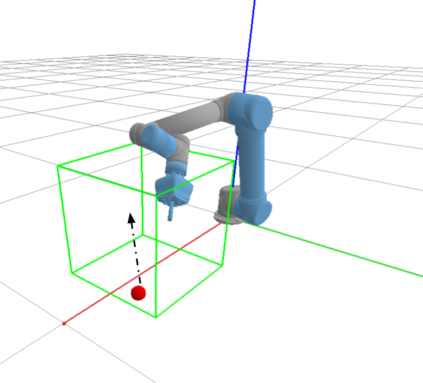
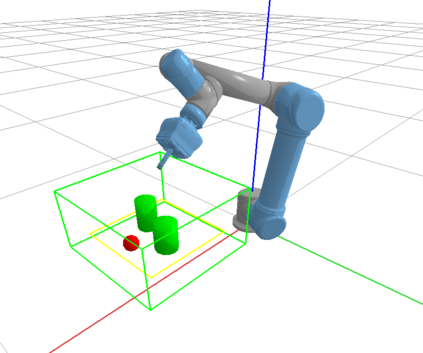
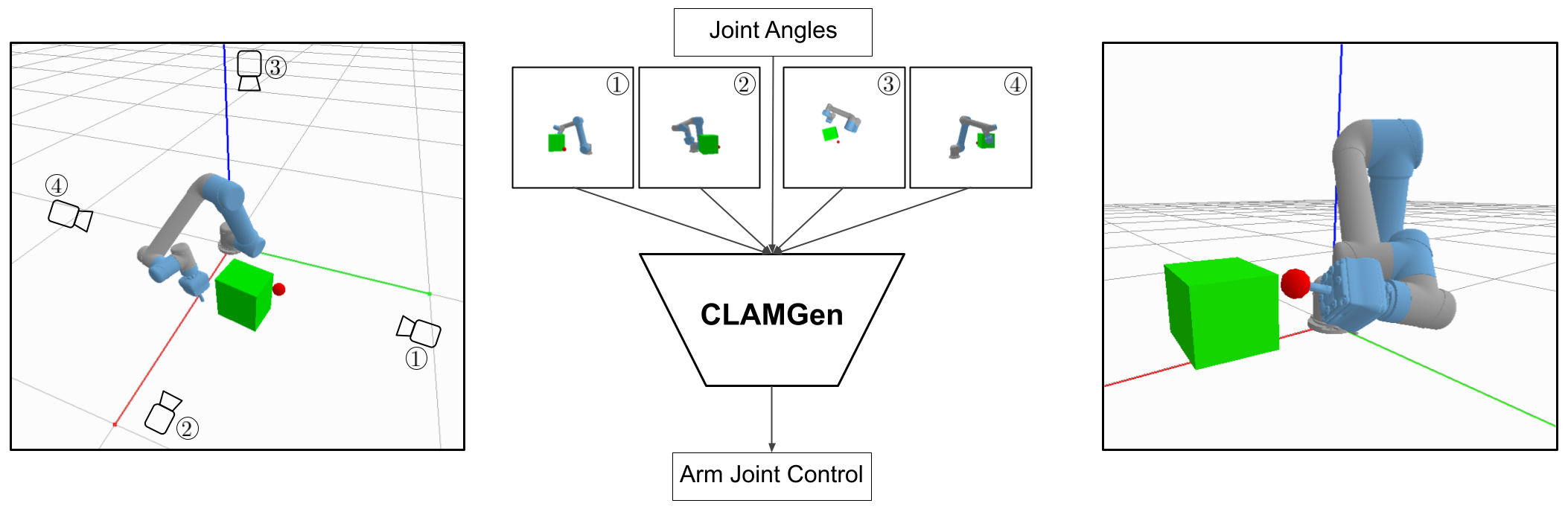
We propose a vision-based reinforcement learning (RL) approach for closed-loop trajectory generation in an arm reaching problem. Arm trajectory generation is a fundamental robotics problem which entails finding collision-free paths to move the robot's body (e.g. arm) in order to satisfy a goal (e.g. place end-effector at a point). While classical methods typically require the model of the environment to solve a planning, search or optimization problem, learning-based approaches hold the promise of directly mapping from observations to robot actions. However, learning a collision-avoidance policy using RL remains a challenge for various reasons, including, but not limited to, partial observability, poor exploration, low sample efficiency, and learning instabilities. To address these challenges, we present a residual-RL method that leverages a greedy goal-reaching RL policy as the base to improve exploration, and the base policy is augmented with residual state-action values and residual actions learned from images to avoid obstacles. Further more, we introduce novel learning objectives and techniques to improve 3D understanding from multiple image views and sample efficiency of our algorithm. Compared to RL baselines, our method achieves superior performance in terms of success rate.
翻译:我们建议对闭环轨轨迹生成问题采取基于愿景的强化学习(RL)方法,以在臂上产生问题; 臂轨迹生成是一个根本性的机器人问题,需要找到不碰撞的路径来移动机器人的身体(例如臂),以便达到一个目标(例如,在某一点放置最终效应 ) 。 虽然传统方法通常要求环境模型来解决规划、搜索或优化问题,但基于学习的方法有希望从观察到机器人行动的直接绘图。 然而,由于各种原因,学习使用RL的避免碰撞政策仍然是一项挑战,其中包括但不限于部分可耐性、勘探不良、样本效率低和学习不稳定性。为了应对这些挑战,我们提出了一个残余-RL方法,利用贪婪的、具有目标效果的RL政策作为改进勘探的基础,而基础政策则随着从图像中汲取的残余国家行动价值和残余行动来避免障碍而得到加强。 此外,我们引入新的学习目标和技术,以便从多种图像观点和我们算法的抽样效率中改进3D的理解。 与RL基准相比,我们的方法取得了更高的成功率。