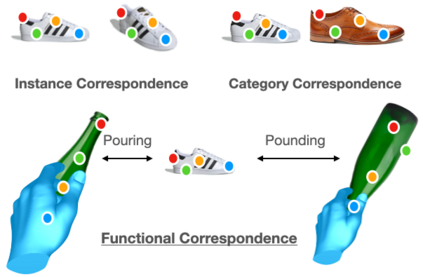
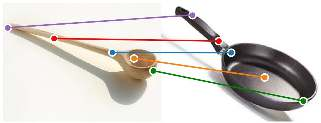
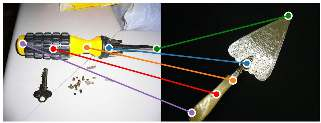
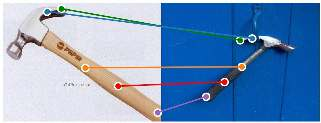
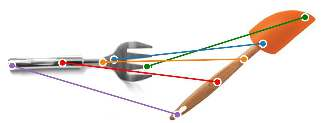
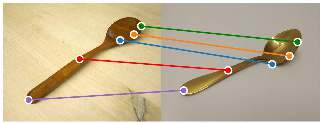
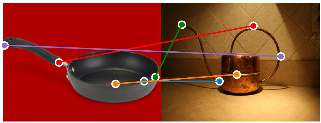
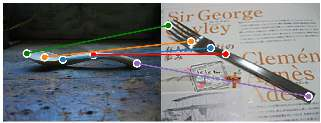
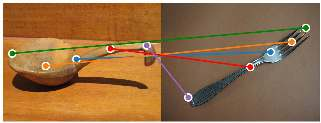
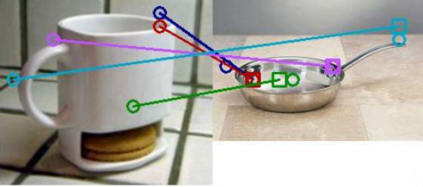
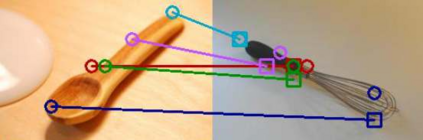
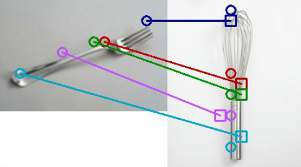
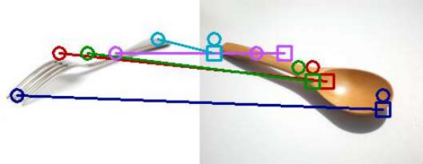
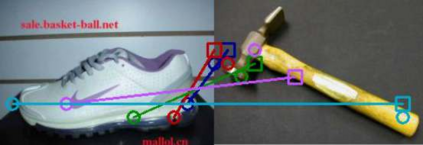
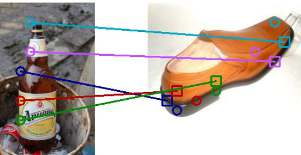
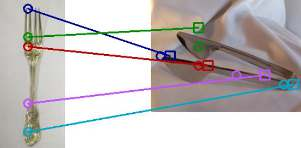
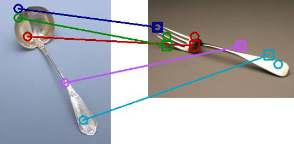
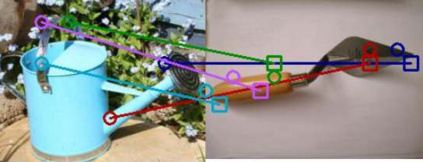
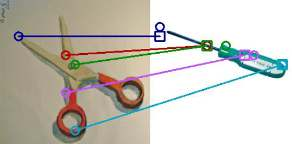
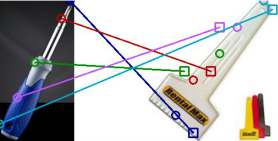
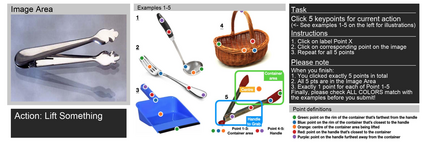
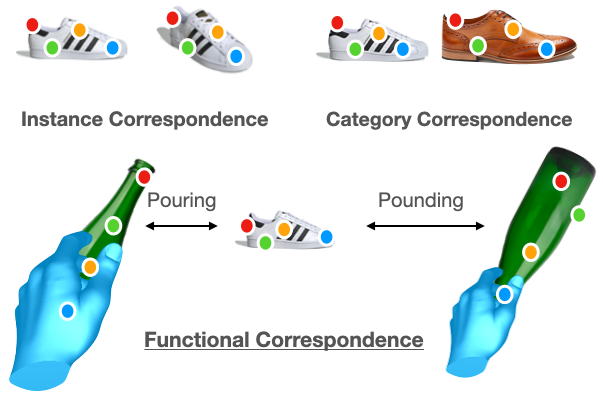
The ability to find correspondences in visual data is the essence of most computer vision tasks. But what are the right correspondences? The task of visual correspondence is well defined for two different images of same object instance. In case of two images of objects belonging to same category, visual correspondence is reasonably well-defined in most cases. But what about correspondence between two objects of completely different category -- e.g., a shoe and a bottle? Does there exist any correspondence? Inspired by humans' ability to: (a) generalize beyond semantic categories and; (b) infer functional affordances, we introduce the problem of functional correspondences in this paper. Given images of two objects, we ask a simple question: what is the set of correspondences between these two images for a given task? For example, what are the correspondences between a bottle and shoe for the task of pounding or the task of pouring. We introduce a new dataset: FunKPoint that has ground truth correspondences for 10 tasks and 20 object categories. We also introduce a modular task-driven representation for attacking this problem and demonstrate that our learned representation is effective for this task. But most importantly, because our supervision signal is not bound by semantics, we show that our learned representation can generalize better on few-shot classification problem. We hope this paper will inspire our community to think beyond semantics and focus more on cross-category generalization and learning representations for robotics tasks.
翻译:在视觉数据中找到通信的能力是大多数计算机视觉任务的实质。 但正确的对应是什么? 视觉通信的任务是什么样的? 视觉通信的任务是对同一对象实例的两个不同图像有明确的定义。 在属于同一类别对象的两个图像中,视觉通信在多数情况下是合理定义的。 但是,对于两个完全不同类别对象 -- -- 例如鞋和瓶子 -- -- 之间的通信来说,视觉通信是什么样的? 是否有任何通信? 受人能力所启发的: (a) 超越语义类和(b) 推断功能性负担能力, 我们在这个文件中引入功能性通信问题。 鉴于两个对象的图像, 我们问一个简单的问题: 这两个图像之间有哪些属于同一类别, 视觉通信在多数情况下是相当的。 例如, 瓶和鞋之间的通信是什么样的通信, 用于打击任务或倾注任务。 我们引入一个新的数据集: 调控点有10项任务和20种对象类的地面对真理通信的定位。 我们还引入一个模块化任务驱动的演示来解决这一问题, 并且证明我们所学到的表达方式对于这项任务来说是有效的。 但是最重要的是, 我们的信号是学习了我们一般的图像, 我们学习了对面的演示 的演示会 将多少 。