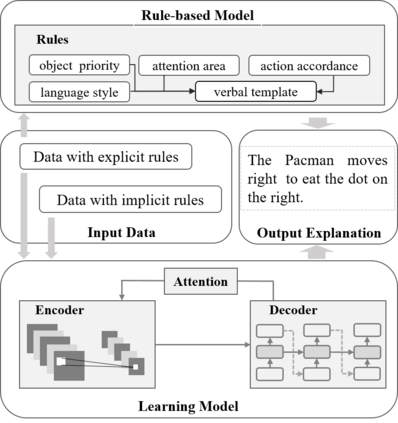
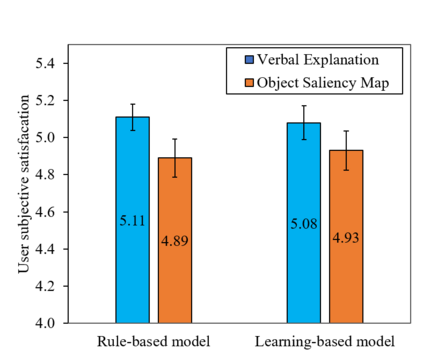
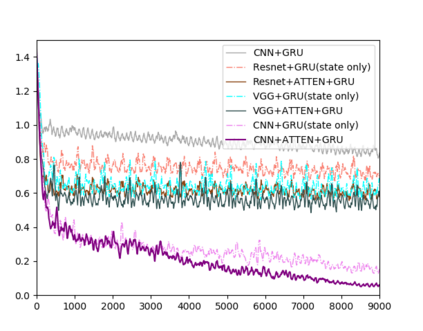
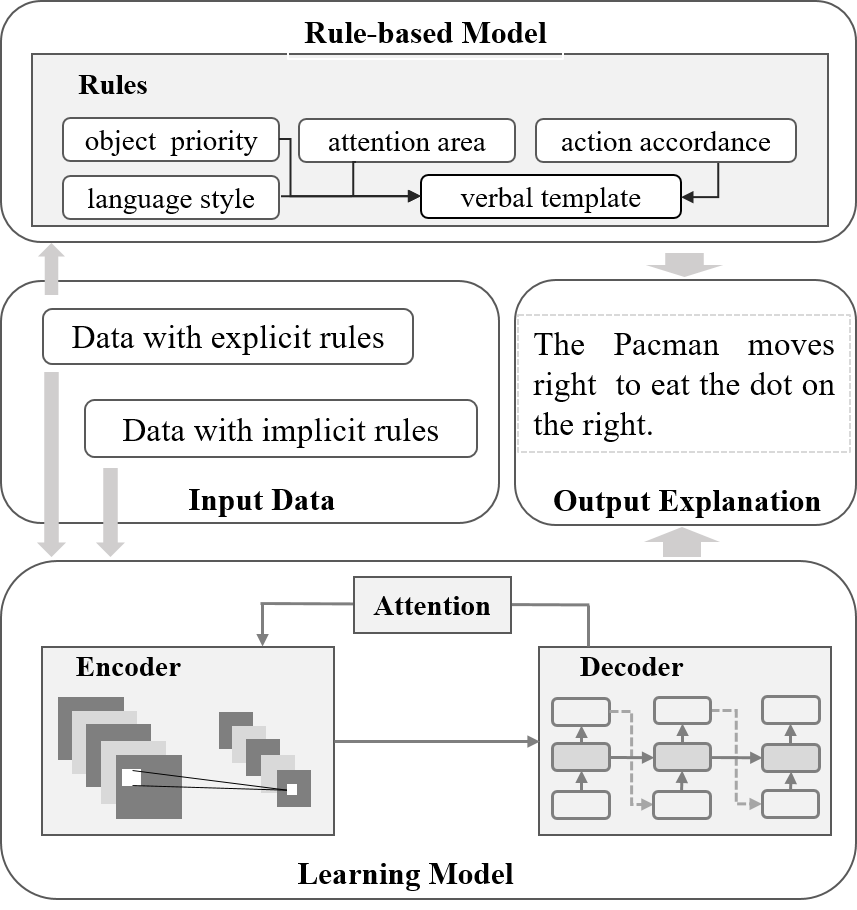
Recently, there has been increasing interest in transparency and interpretability in Deep Reinforcement Learning (DRL) systems. Verbal explanations, as the most natural way of communication in our daily life, deserve more attention, since they allow users to gain a better understanding of the system which ultimately could lead to a high level of trust and smooth collaboration. This paper reports a novel work in generating verbal explanations for DRL behaviors agent. A rule-based model is designed to construct explanations using a series of rules which are predefined with prior knowledge. A learning model is then proposed to expand the implicit logic of generating verbal explanation to general situations by employing rule-based explanations as training data. The learning model is shown to have better flexibility and generalizability than the static rule-based model. The performance of both models is evaluated quantitatively through objective metrics. The results show that verbal explanation generated by both models improve subjective satisfaction of users towards the interpretability of DRL systems. Additionally, seven variants of the learning model are designed to illustrate the contribution of input channels, attention mechanism, and proposed encoder in improving the quality of verbal explanation.
翻译:最近,人们对深入强化学习(DRL)系统的透明度和可解释性越来越感兴趣。口头解释作为我们日常生活中最自然的沟通方式,值得更多关注,因为口头解释使用户能够更好地了解最终可导致高度信任和顺利合作的系统。本文报告了为DRL行为代理提供口头解释的新工作。基于规则的模式旨在利用一系列事先以知识预先界定的规则来构建解释。然后建议采用学习模式,通过使用基于规则的解释作为培训数据,扩大对一般情况的口头解释的隐含逻辑。学习模式比基于规则的固定模式具有更大的灵活性和可概括性。两种模式的业绩都通过客观的衡量标准进行定量评价。结果显示,两种模式产生的口头解释提高了用户对DRL系统的可解释性的主观满意度。此外,学习模式的七个变式旨在说明投入渠道、注意机制和拟议的编码在提高口头解释质量方面的贡献。