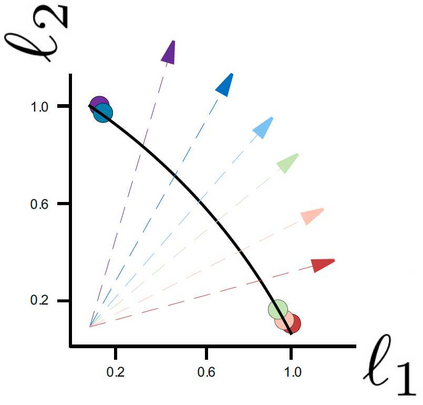
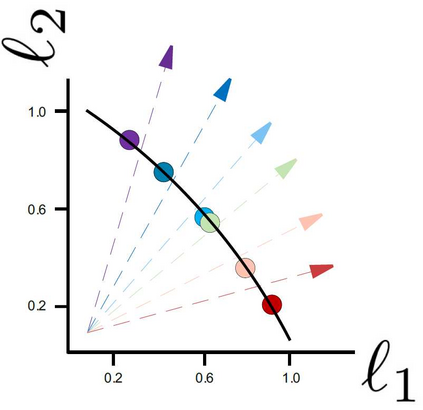
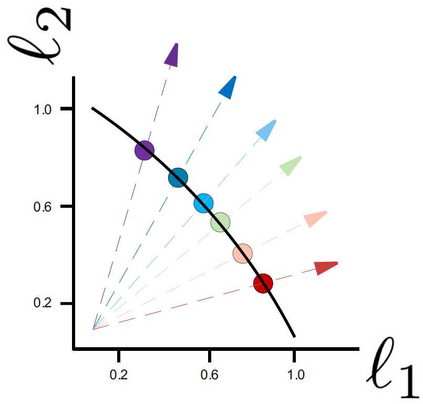
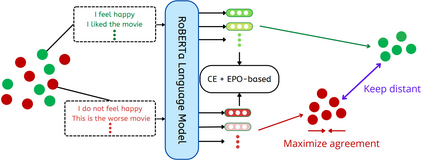
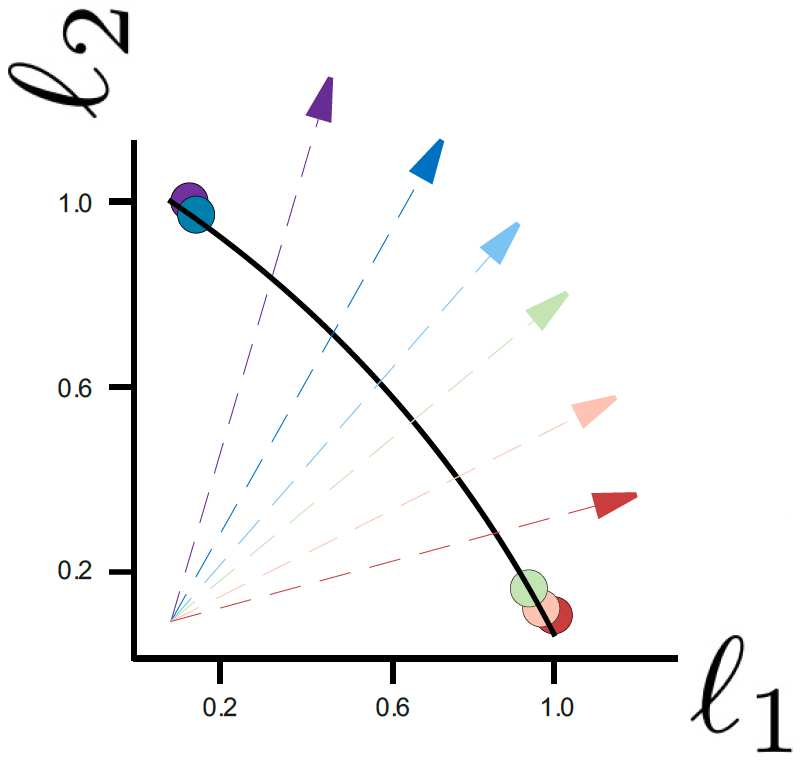
Recently, Supervised Contrastive Learning (SCL) has been shown to achieve excellent performance in most classification tasks. In SCL, a neural network is trained to optimize two objectives: pull an anchor and positive samples together in the embedding space, and push the anchor apart from the negatives. However, these two different objectives may conflict, requiring trade-offs between them during optimization. In this work, we formulate the SCL problem as a Multi-Objective Optimization problem for the fine-tuning phase of RoBERTa language model. Two methods are utilized to solve the optimization problem: (i) the linear scalarization (LS) method, which minimizes a weighted linear combination of pertask losses; and (ii) the Exact Pareto Optimal (EPO) method which finds the intersection of the Pareto front with a given preference vector. We evaluate our approach on several GLUE benchmark tasks, without using data augmentations, memory banks, or generating adversarial examples. The empirical results show that the proposed learning strategy significantly outperforms a strong competitive contrastive learning baseline
翻译:最近,监督反向学习(SCL)在大多数分类任务中表现优异。在SCL,神经网络经过培训,优化了两个目标:(一) 线性缩放法(LS),将嵌入空间的加权线性组合,将正样样本拉到一起,并将锚定除在负值之外。然而,这两个不同的目标可能相互冲突,要求在优化过程中相互取舍。在这项工作中,我们将SCL问题作为罗贝塔语言模型微调阶段的多目标性优化问题来制定。使用了两种方法来解决优化问题:(一) 线性缩放法(LS),该方法最大限度地减少了孔径损失的加权线性组合;(二) Exact Pareto Apptimal(EPO) 方法,该方法发现帕雷托前端与给定的偏向量的交叉点。我们评估了我们在若干GLUE基准任务上的方法,而没有使用数据增强、记忆库或生成对抗性实例。经验结果显示,拟议的学习战略大大超出了一个有力的竞争性对比学习基线。