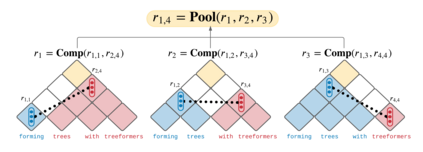
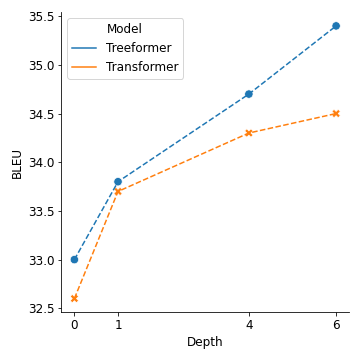
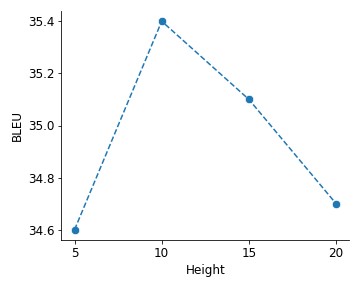
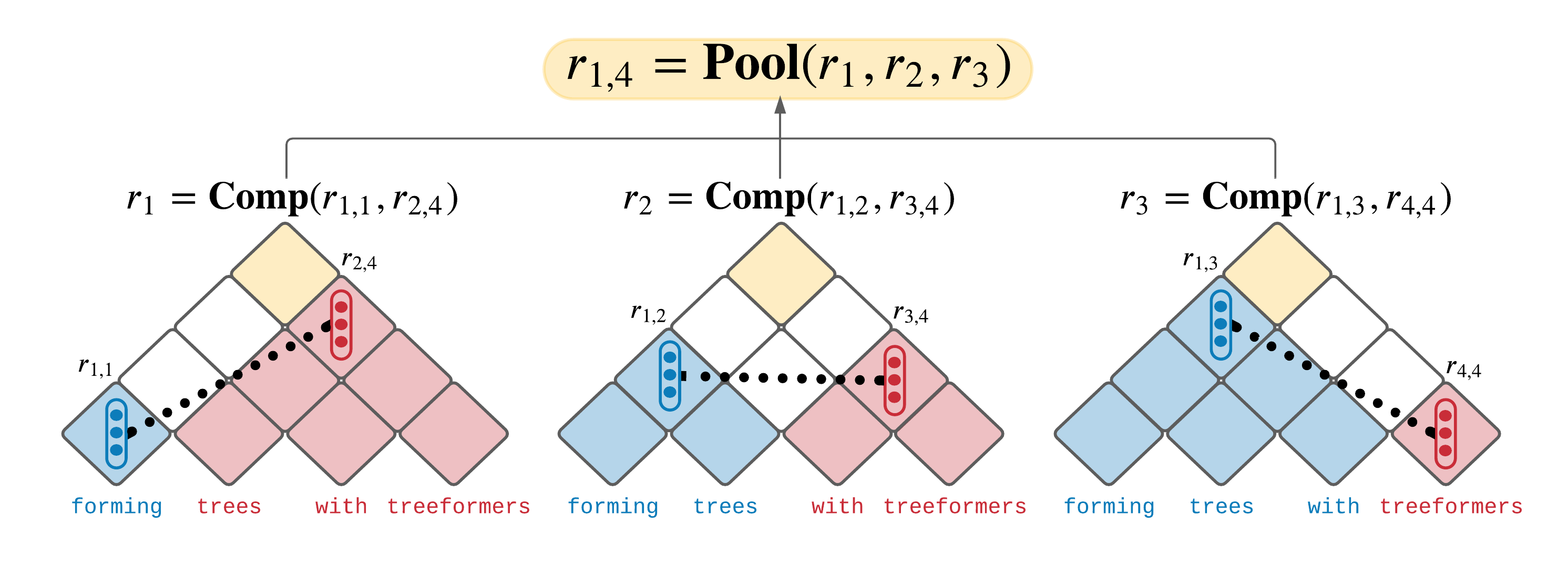
Popular models such as Transformers and LSTMs use tokens as its unit of information. That is, each token is encoded into a vector representation, and those vectors are used directly in a computation. However, humans frequently consider spans of tokens (i.e., phrases) instead of their constituent tokens. In this paper we introduce Treeformer, an architecture inspired by the CKY algorithm and Transformer which learns a composition operator and pooling function in order to construct hierarchical encodings for phrases and sentences. Our extensive experiments demonstrate the benefits of incorporating a hierarchical structure into the Transformer, and show significant improvements compared to a baseline Transformer in machine translation, abstractive summarization, and various natural language understanding tasks.
翻译:诸如变换器和 LSTMs 等流行模型使用符号作为其信息单位。 也就是说, 每种代号都编码成矢量表示法, 而这些代号直接用于计算。 但是, 人类经常会考虑代号( 短语) 的跨度, 而不是其组成代号 。 在本文中, 我们引入了由 CKY 算法和变换器所启发的架构Treeforn, 这个架构受CKY 算法和变换器的启发, 学习一个组成操作器和组合功能, 以构建短语和句子的等级编码 。 我们的广泛实验展示了将等级结构纳入变换器的好处, 并展示了与机器翻译、 抽象组合和各种自然语言理解任务中的基准变换器相比的重大改进 。