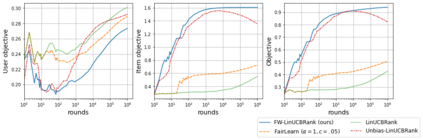
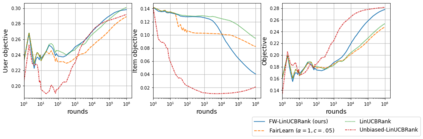
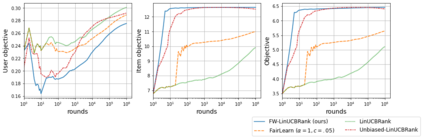
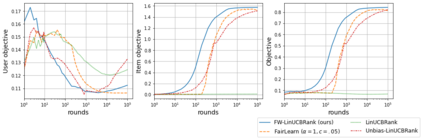
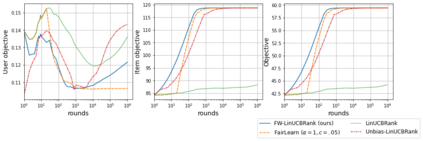
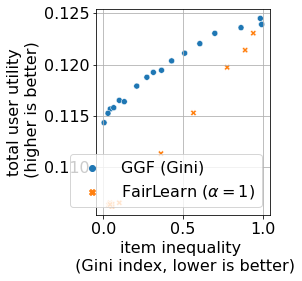
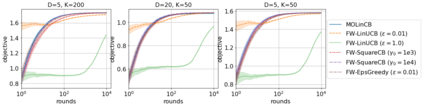
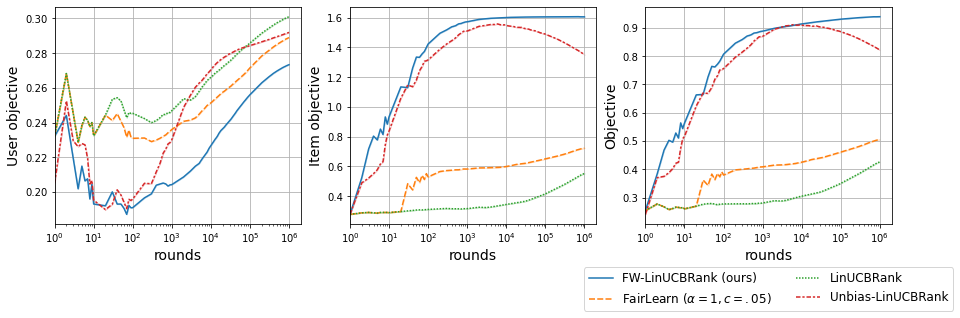
We consider Contextual Bandits with Concave Rewards (CBCR), a multi-objective bandit problem where the desired trade-off between the rewards is defined by a known concave objective function, and the reward vector depends on an observed stochastic context. We present the first algorithm with provably vanishing regret for CBCR without restrictions on the policy space, whereas prior works were restricted to finite policy spaces or tabular representations. Our solution is based on a geometric interpretation of CBCR algorithms as optimization algorithms over the convex set of expected rewards spanned by all stochastic policies. Building on Frank-Wolfe analyses in constrained convex optimization, we derive a novel reduction from the CBCR regret to the regret of a scalar-reward bandit problem. We illustrate how to apply the reduction off-the-shelf to obtain algorithms for CBCR with both linear and general reward functions, in the case of non-combinatorial actions. Motivated by fairness in recommendation, we describe a special case of CBCR with rankings and fairness-aware objectives, leading to the first algorithm with regret guarantees for contextual combinatorial bandits with fairness of exposure.
翻译:我们考虑的是Concave Rewards(CBCR)的“背景强盗”问题,这是一个多目标的强盗问题,其原因是,通过已知的 concave 目标功能界定了奖赏之间的预期权衡,而奖赏矢量则取决于观察到的随机环境。我们提出了第一个算法,在没有限制政策空间的情况下,CBCR对CBR的遗憾可以明显消失,而以前的工作仅限于有限的政策空间或表示。我们的解决办法是基于对CBCR算法的几何解释,将CBCR算法作为所有随机政策的预期奖赏范围组合的优化算法。在限制 convex优化的Frank-Wolfe分析的基础上,我们从CBCR得出了新颖的减法,结果就是对Scalar-Reward 土匪问题的遗憾。我们演示了如何将现在的减法用于获得CBCRCRCR的算法,在非combinal 行动方面都有线性和一般奖赏功能。受建议公平激励,我们描述了CBCCCRCRICCRind-awa relaveal laveal asim vial lagal sh