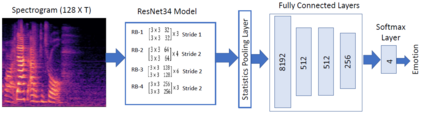
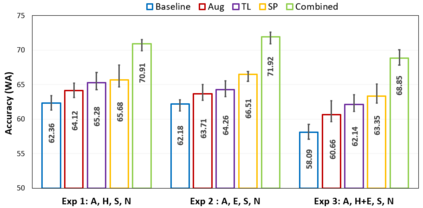
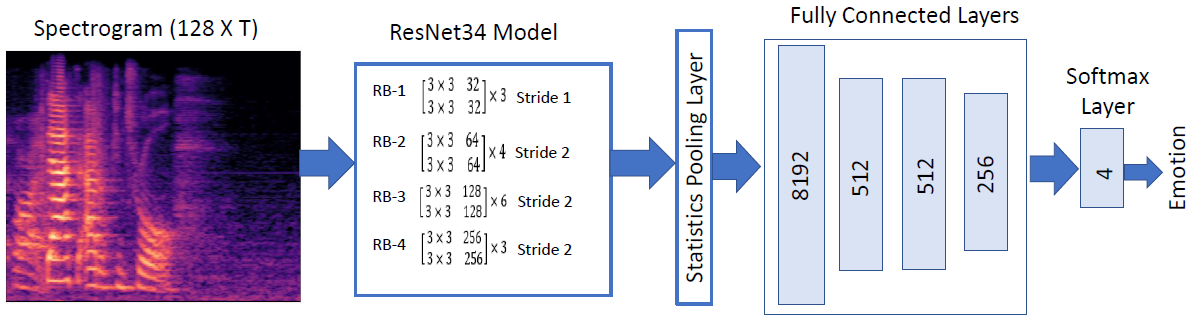
Automatic speech emotion recognition (SER) is a challenging task that plays a crucial role in natural human-computer interaction. One of the main challenges in SER is data scarcity, i.e., insufficient amounts of carefully labeled data to build and fully explore complex deep learning models for emotion classification. This paper aims to address this challenge using a transfer learning strategy combined with spectrogram augmentation. Specifically, we propose a transfer learning approach that leverages a pre-trained residual network (ResNet) model including a statistics pooling layer from speaker recognition trained using large amounts of speaker-labeled data. The statistics pooling layer enables the model to efficiently process variable-length input, thereby eliminating the need for sequence truncation which is commonly used in SER systems. In addition, we adopt a spectrogram augmentation technique to generate additional training data samples by applying random time-frequency masks to log-mel spectrograms to mitigate overfitting and improve the generalization of emotion recognition models. We evaluate the effectiveness of our proposed approach on the interactive emotional dyadic motion capture (IEMOCAP) dataset. Experimental results indicate that the transfer learning and spectrogram augmentation approaches improve the SER performance, and when combined achieve state-of-the-art results.
翻译:自动言语情绪识别(SER)是一项具有挑战性的任务,在人与计算机的自然互动中发挥着关键作用。SER的主要挑战之一是数据稀缺,即没有足够数量经过仔细标记的数据来建立和充分探索复杂的情感分类深层学习模式。本文件旨在利用转让学习战略以及光谱增强来应对这一挑战。具体地说,我们建议采用转让学习方法,利用预先培训的残余网络(ResNet)模型,包括使用大量语音标签数据培训的语音识别的统计集合层。统计数据集合层使模型能够高效处理变长输入,从而消除SER系统中常用的序列脱线需求。此外,我们采用光谱增强技术,通过随机使用时频掩光仪来生成更多的培训数据样本,以缓解对情绪识别模型的过度调整和改进。我们评估了我们提议的交互式情感运动捕获方法(IEMOCAP)的有效性。实验结果表明,转移学习和光谱扩增方法提高了SER的性能,并在实现综合状态时实现了结果。