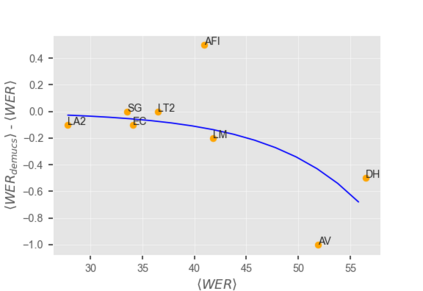
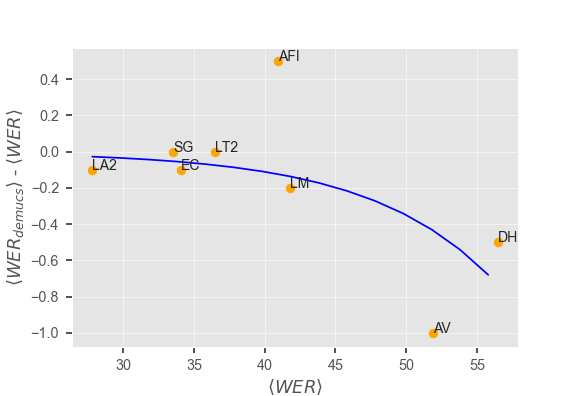
This paper describes joint effort of BUT and Telef\'onica Research on development of Automatic Speech Recognition systems for Albayzin 2020 Challenge. We compare approaches based on either hybrid or end-to-end models. In hybrid modelling, we explore the impact of SpecAugment layer on performance. For end-to-end modelling, we used a convolutional neural network with gated linear units (GLUs). The performance of such model is also evaluated with an additional n-gram language model to improve word error rates. We further inspect source separation methods to extract speech from noisy environment (i.e. TV shows). More precisely, we assess the effect of using a neural-based music separator named Demucs. A fusion of our best systems achieved 23.33% WER in official Albayzin 2020 evaluations. Aside from techniques used in our final submitted systems, we also describe our efforts in retrieving high quality transcripts for training.
翻译:本文介绍BET和Telef\'onica研究公司在为Albayzin2020挑战开发自动语音识别系统方面的联合努力。我们比较基于混合或端到端模式的方法。在混合模型中,我们探索了分层层对性能的影响。在端到端模型中,我们使用了带有门线单元(GLUs)的进化神经网络。这种模型的性能还用另外的正方格语言模型来评估,以提高字误差率。我们进一步检查源分离方法,以便从吵闹的环境(即电视节目)中提取语音。更准确地说,我们评估了使用以神经为基础的音乐分离器Demucs的效果。我们最佳系统的结合在官方的Albayzin2020年评价中达到了23.33% WER。除了我们最后提交的系统所使用的技术外,我们还介绍了我们为检索高质量培训记录而做出的努力。