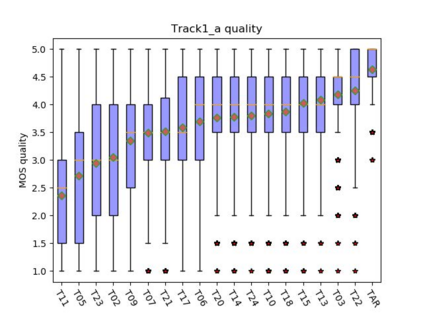
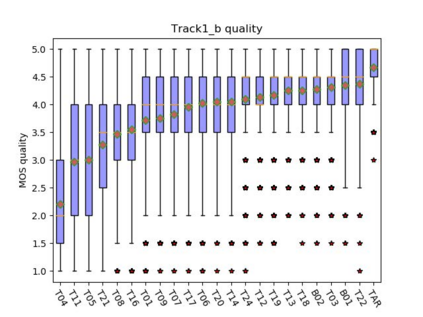
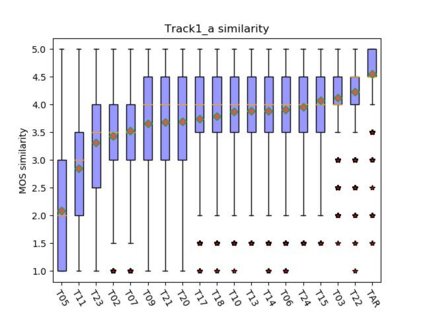
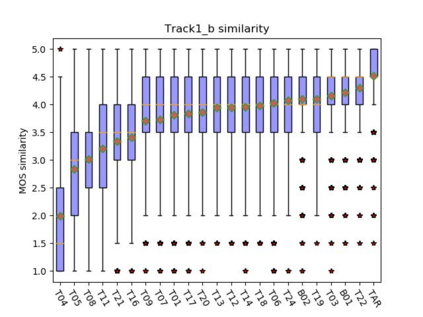
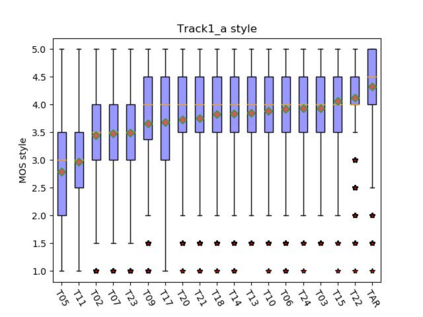
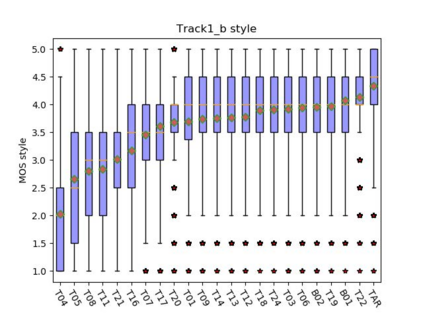
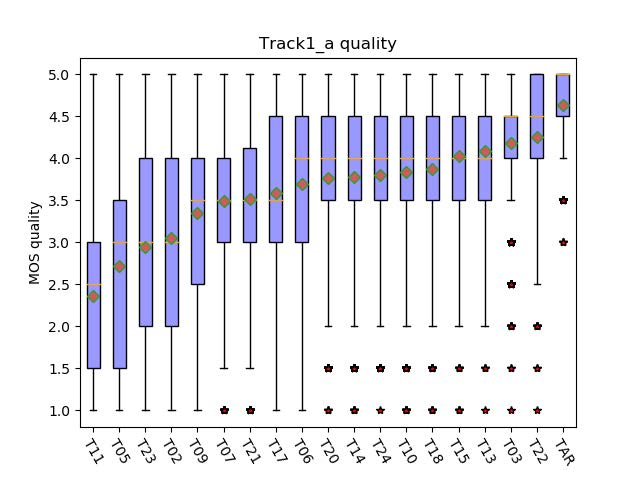
This paper presents the CUHK-EE voice cloning system for ICASSP 2021 M2VoC challenge. The challenge provides two Mandarin speech corpora: the AIShell-3 corpus of 218 speakers with noise and reverberation and the MST corpus including high-quality speech of one male and one female speakers. 100 and 5 utterances of 3 target speakers in different voice and style are provided in track 1 and 2 respectively, and the participants are required to synthesize speech in target speaker's voice and style. We take part in the track 1 and carry out voice cloning based on 100 utterances of target speakers. An end-to-end voicing cloning system is developed to accomplish the task, which includes: 1. a text and speech front-end module with the help of forced alignment, 2. an acoustic model combining Tacotron2 and DurIAN to predict melspectrogram, 3. a Hifigan vocoder for waveform generation. Our system comprises three stages: multi-speaker training stage, target speaker adaption stage and target speaker synthesis stage. Our team is identified as T17. The subjective evaluation results provided by the challenge organizer demonstrate the effectiveness of our system. Audio samples are available at our demo page: https://daxintan-cuhk.github.io/CUHK-EE-system-M2VoC-challenge/ .
翻译:本文介绍了ICASSP 2021 M2VoC 的CUHK-EE语音克隆系统挑战。挑战提供了两种普通话语调:AHEL-3系统,218个讲者,其中有噪音和回响,还有MST系统,包括一名男讲者和一名女讲者高质量的发言。第1和第2轨中分别提供了100和5个讲3个不同声音和风格的目标发言者的语音系统。参与者需要用目标发言者的声音和风格综合发言。我们参加第1轨,并根据目标发言者的100次发言进行语音克隆。我们团队被确定为T17。我们团队的终端至终端发声克隆系统为完成这一任务,其中包括:1个文本和发言前端模块,有强迫调整的帮助;2个将Tacotron2和Durian综合3个不同声音和风格的3个声音和5个声音和3个目标发言者的声调模型,以及波形一代的Hiffigan vocoder。我们系统分为三个阶段:多讲者培训阶段,目标发言者调整舞台和目标发言者合成阶段。我们团队被确定为T17。我们小组提供的主观-CUPRO-C/CU/SU 显示我们的挑战系统。