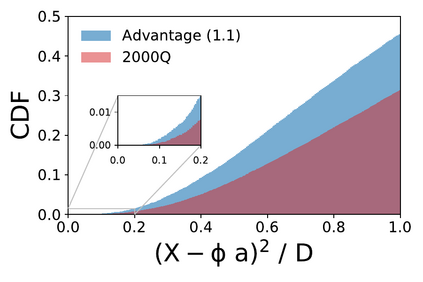
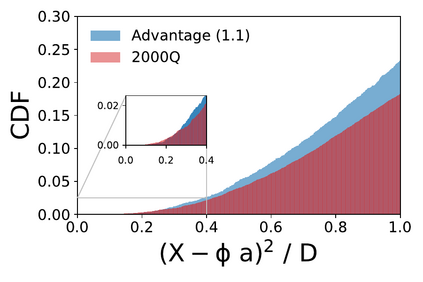
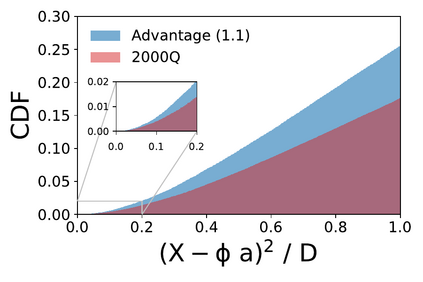
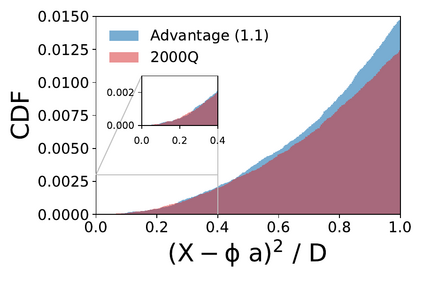
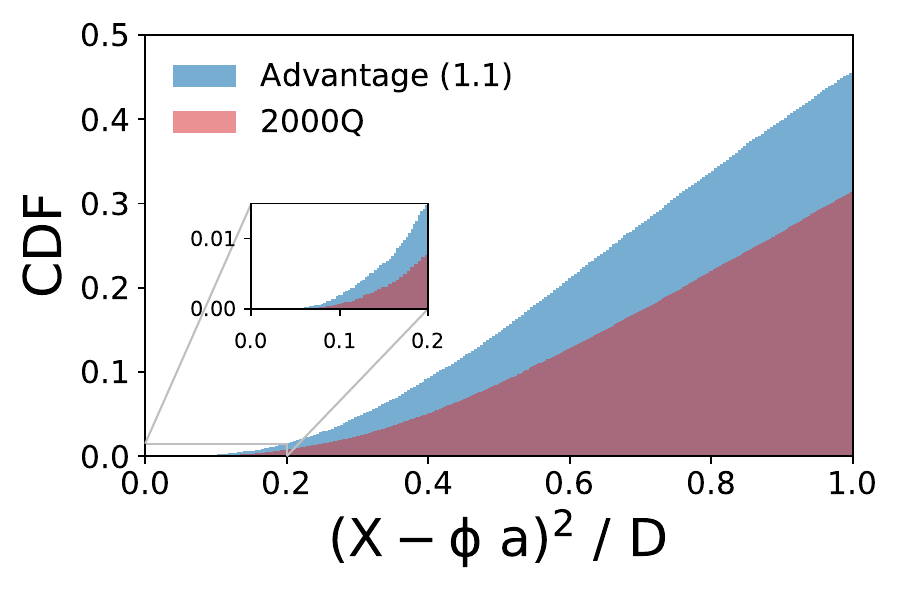
We present a new lossy compression algorithm for statistical floating-point data through a representation learning with binary variables. The algorithm finds a set of basis vectors and their binary coefficients that precisely reconstruct the original data. The optimization for the basis vectors is performed classically, while binary coefficients are retrieved through both simulated and quantum annealing for comparison. A bias correction procedure is also presented to estimate and eliminate the error and bias introduced from the inexact reconstruction of the lossy compression for statistical data analyses. The compression algorithm is demonstrated on two different datasets of lattice quantum chromodynamics simulations. The results obtained using simulated annealing show 3.5 times better compression performance than the algorithms based on a neural-network autoencoder and principal component analysis. Calculations using quantum annealing also show promising results, but performance is limited by the integrated control error of the quantum processing unit, which yields large uncertainties in the biases and coupling parameters. Hardware comparison is further studied between the previous generation D-Wave 2000Q and the current D-Wave Advantage system. Our study shows that the Advantage system is more likely to obtain low-energy solutions for the problems than the 2000Q.
翻译:我们通过用二进制变量进行代表式学习,为统计浮点数据提出了一个新的损失压缩算法。算法发现一套基础矢量及其二进制系数,精确地重建原始数据。基础矢量的优化是典型的,而二进制系数则通过模拟和量子肛门取回,以供比较。还提出了偏向修正程序,以估计和消除在不精确地重建损失压缩以进行统计数据分析过程中出现的错误和偏差。压缩算法在两个不同的拉蒂斯量子铬动力模拟数据集中得到了演示。使用模拟肛门计算的结果显示的压缩性能比基于神经-网络自动编码和主要部件分析的算法要好3.5倍。使用量子内存的计算也显示了有希望的结果,但是由于量子处理器的综合控制错误使偏差和组合参数产生很大的不确定性,因此其性能受到了限制。在前一代D-Wave 2000Q 和当前的D-Wave Advantage系统之间进行了硬比较。在前一代D-Wave Advantage Q 之间进一步研究了硬软件的比较。我们的研究显示,Advanage-vanage 系统可能比低能源系统更难于2000 Q。