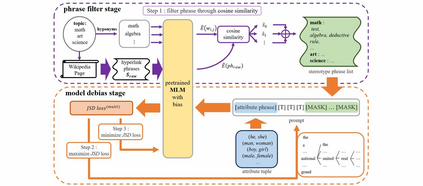
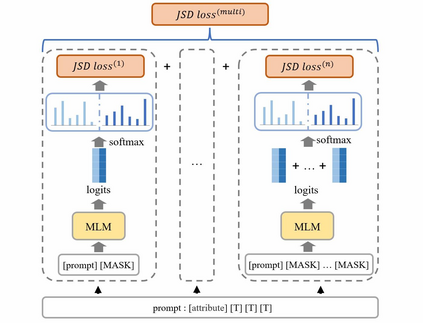
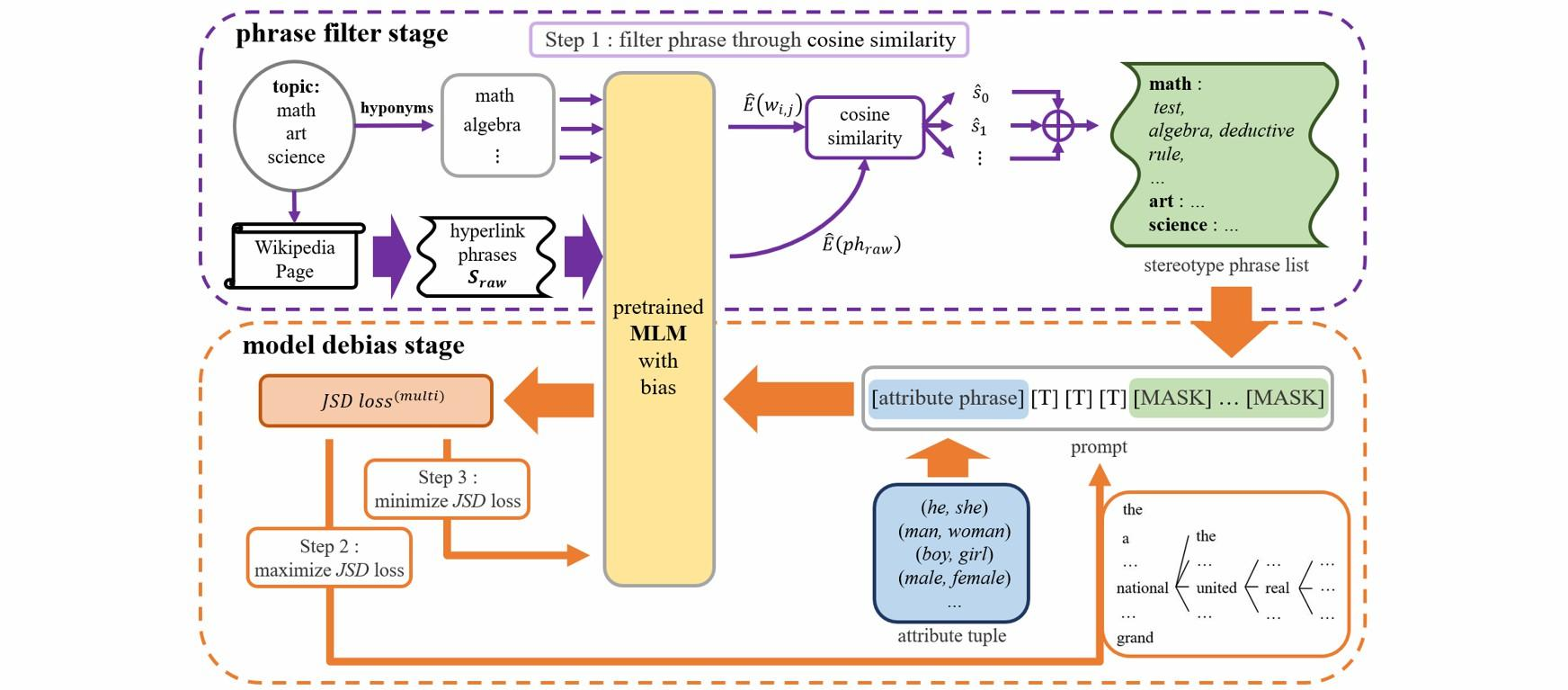
The social biases and unwelcome stereotypes revealed by pretrained language models are becoming obstacles to their application. Compared to numerous debiasing methods targeting word level, there has been relatively less attention on biases present at phrase level, limiting the performance of debiasing in discipline domains. In this paper, we propose an automatic multi-token debiasing pipeline called \textbf{General Phrase Debiaser}, which is capable of mitigating phrase-level biases in masked language models. Specifically, our method consists of a \textit{phrase filter stage} that generates stereotypical phrases from Wikipedia pages as well as a \textit{model debias stage} that can debias models at the multi-token level to tackle bias challenges on phrases. The latter searches for prompts that trigger model's bias, and then uses them for debiasing. State-of-the-art results on standard datasets and metrics show that our approach can significantly reduce gender biases on both career and multiple disciplines, across models with varying parameter sizes.
翻译:暂无翻译