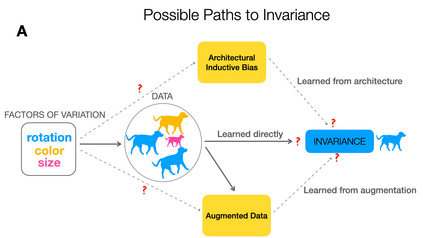
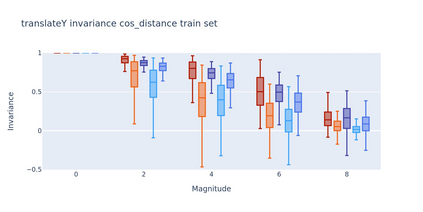
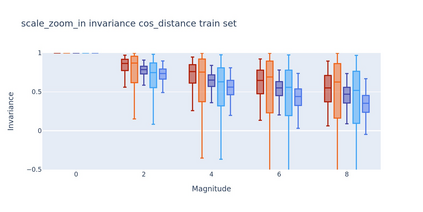
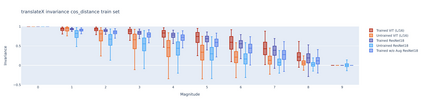
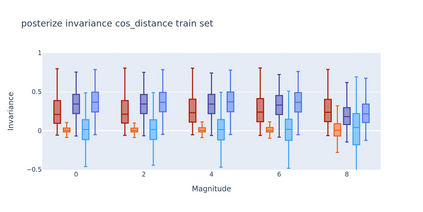
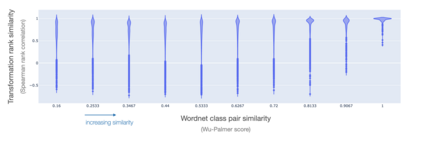
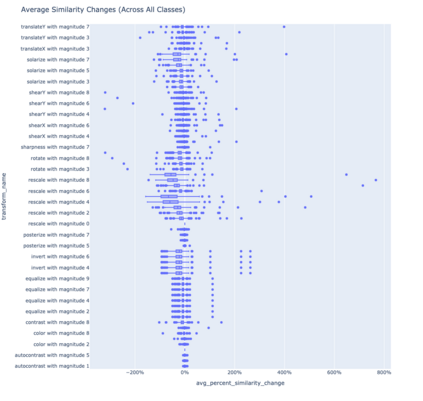
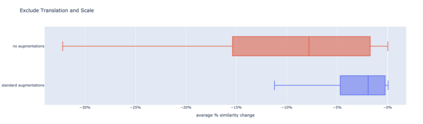
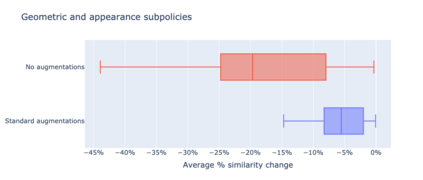
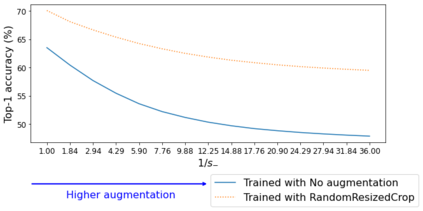
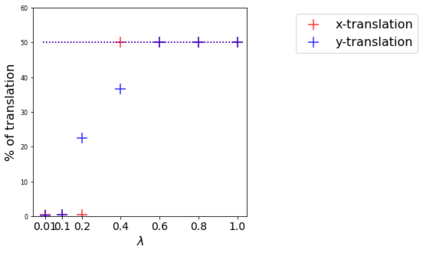
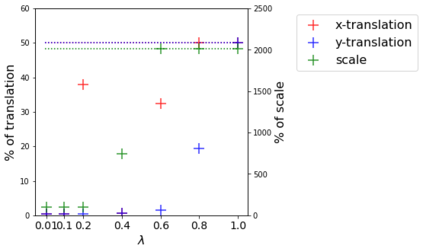
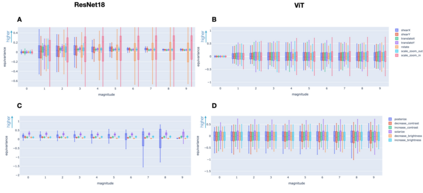
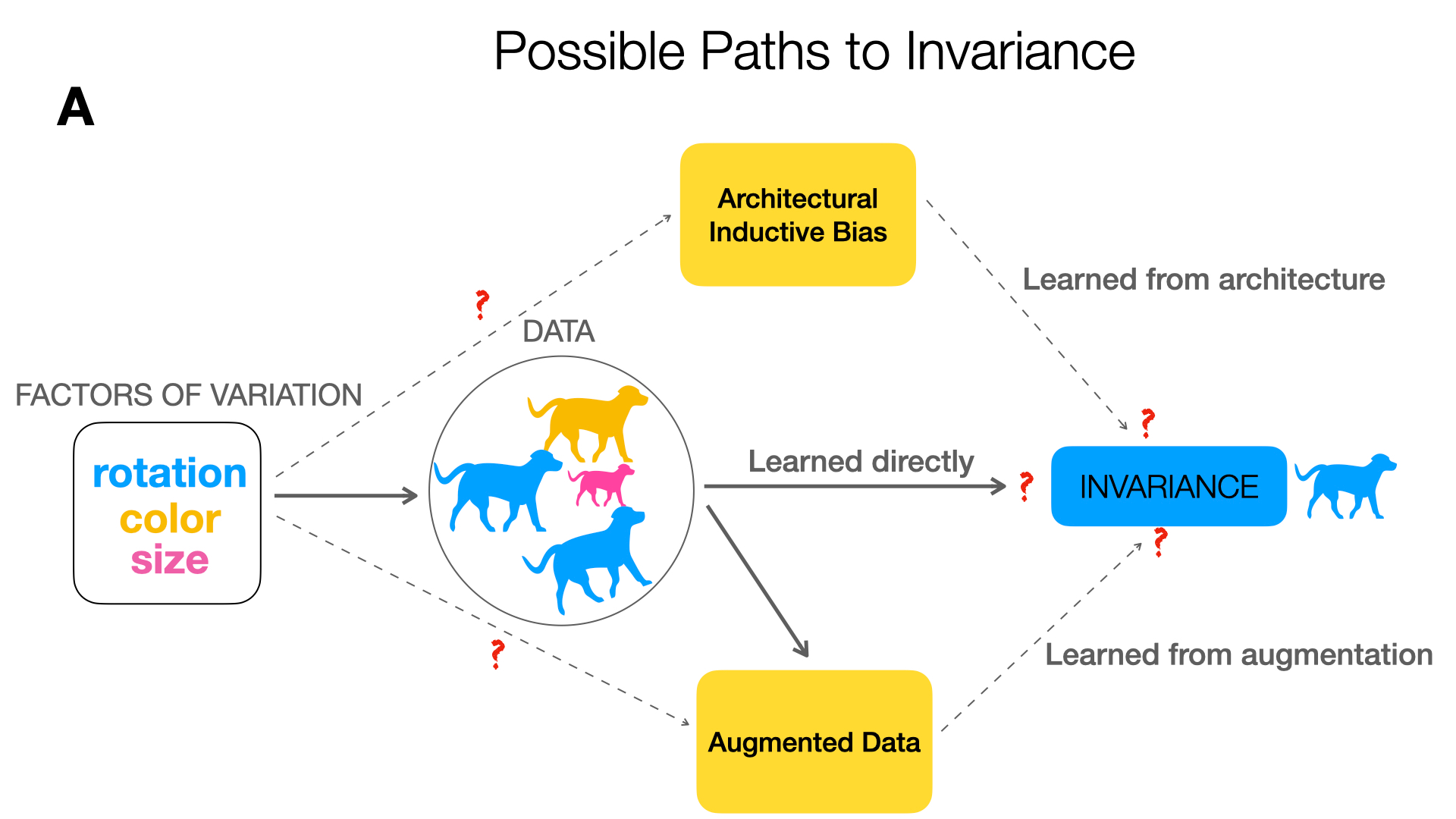
To perform well on unseen and potentially out-of-distribution samples, it is desirable for machine learning models to have a predictable response with respect to transformations affecting the factors of variation of the input. Invariance is commonly achieved through hand-engineered data augmentation, but do standard data augmentations address transformations that explain variations in real data? While prior work has focused on synthetic data, we attempt here to characterize the factors of variation in a real dataset, ImageNet, and study the invariance of both standard residual networks and the recently proposed vision transformer with respect to changes in these factors. We show standard augmentation relies on a precise combination of translation and scale, with translation recapturing most of the performance improvement -- despite the (approximate) translation invariance built in to convolutional architectures, such as residual networks. In fact, we found that scale and translation invariance was similar across residual networks and vision transformer models despite their markedly different inductive biases. We show the training data itself is the main source of invariance, and that data augmentation only further increases the learned invariances. Interestingly, the invariances brought from the training process align with the ImageNet factors of variation we found. Finally, we find that the main factors of variation in ImageNet mostly relate to appearance and are specific to each class.
翻译:为了在不可见的和可能无法分配的样本上取得良好表现,机器学习模型最好能够对影响投入变化因素的变异做出可预测的反应。惯用数据增强通常通过手工设计的数据实现,但标准数据增强处理解释真实数据变化的变异?虽然以前的工作侧重于合成数据,但我们试图在这里辨别真实数据集、图像网和图像网的差异因素,并研究标准残余网络和最近就这些因素变化提议的愿景变异器的不易性。我们显示,标准增强依赖于翻译和规模的精确组合,而翻译则恢复了大部分性能改进 -- -- 尽管(近似)变异性是建在革命结构中,例如残余网络。事实上,我们发现,尽管残余网络和愿景变异模型具有明显的感性偏差,但规模和变异性在剩余网络和视觉变变模型中是相似的。我们显示,培训数据本身是变化的主要来源,而数据增加仅进一步增加所学的变异性。有趣的是,从我们所发现的主要图像变异性因素,最终从我们所发现的每个图像变异性因素到我们所发现的主要变异性。