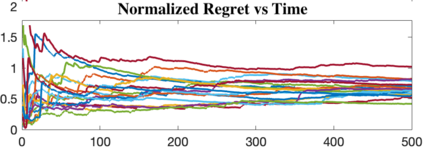
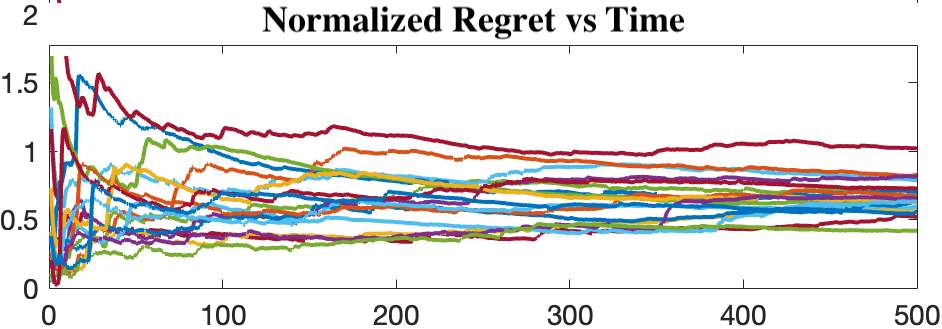
This work studies theoretical performance guarantees of a ubiquitous reinforcement learning policy for controlling the canonical model of stochastic linear-quadratic system. We show that randomized certainty equivalent policy addresses the exploration-exploitation dilemma for minimizing quadratic costs in linear dynamical systems that evolve according to stochastic differential equations. More precisely, we establish square-root of time regret bounds, indicating that randomized certainty equivalent policy learns optimal control actions fast from a single state trajectory. Further, linear scaling of the regret with the number of parameters is shown. The presented analysis introduces novel and useful technical approaches, and sheds light on fundamental challenges of continuous-time reinforcement learning.
翻译:这项工作研究为控制随机线性赤道系统的罐体模型而普遍强化学习政策的理论性能保障理论性能保障。我们表明,随机性确定等效政策解决了在根据随机性差异方程式演变而成的线性动态系统中最大限度地降低二次成本的探索-开发两难困境。更准确地说,我们建立了时间遗憾界限的平方根,表明随机性等同政策能够快速从单一的状态轨迹中学习最佳控制行动。此外,还展示了对参数数的遗憾的线性缩放。所提供的分析介绍了新颖和有用的技术方法,并揭示了持续时间强化学习的基本挑战。