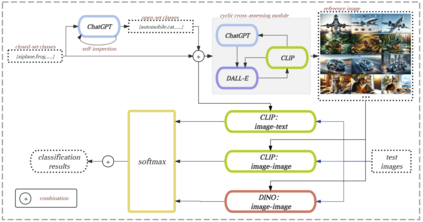
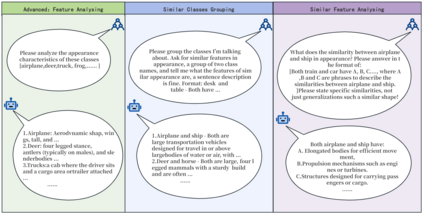
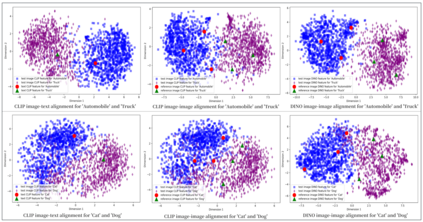
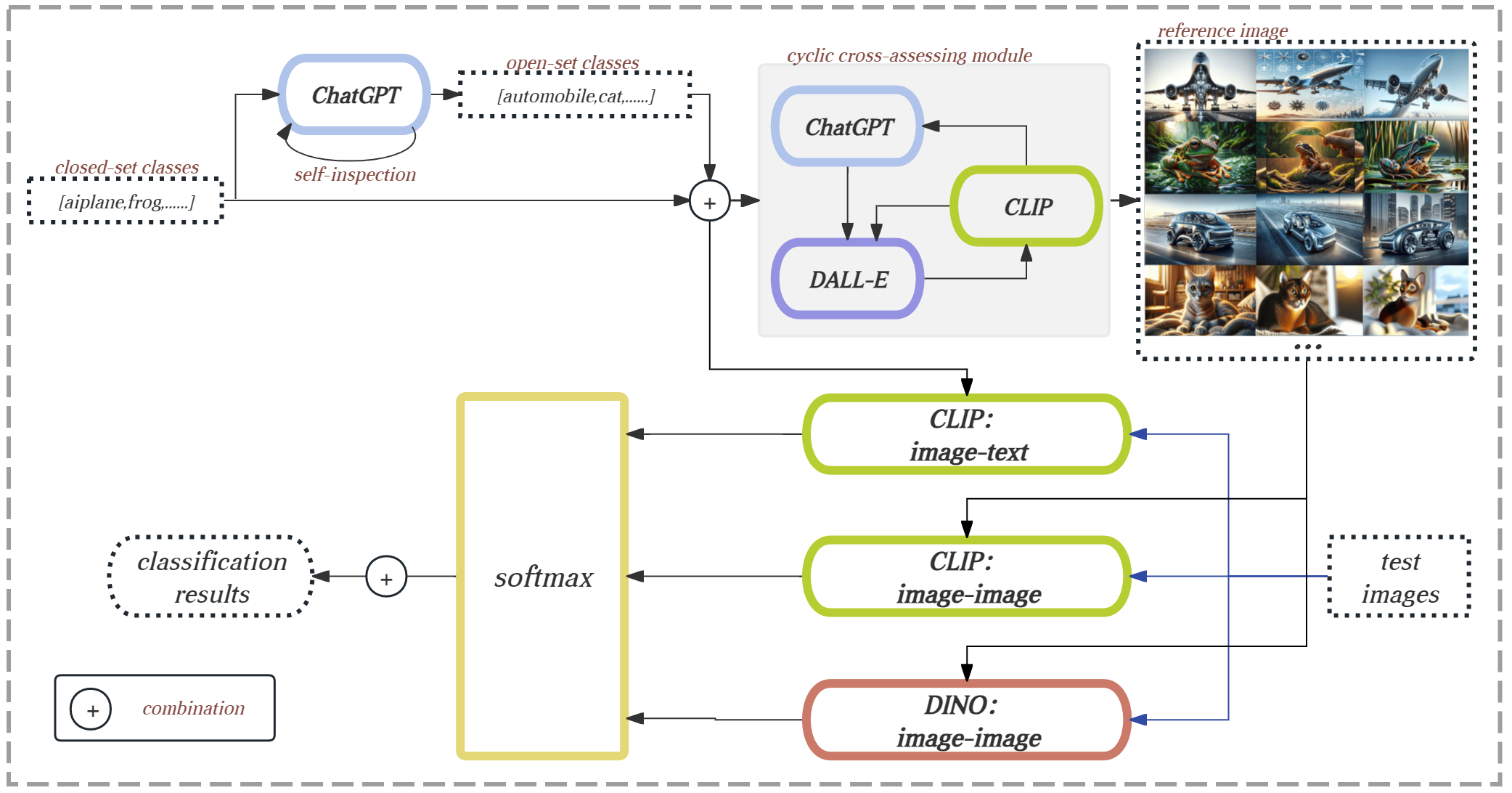
This paper introduces a novel framework for zero-shot learning (ZSL), i.e., to recognize new categories that are unseen during training, by using a multi-model and multi-alignment integration method. Specifically, we propose three strategies to enhance the model's performance to handle ZSL: 1) Utilizing the extensive knowledge of ChatGPT and the powerful image generation capabilities of DALL-E to create reference images that can precisely describe unseen categories and classification boundaries, thereby alleviating the information bottleneck issue; 2) Integrating the results of text-image alignment and image-image alignment from CLIP, along with the image-image alignment results from DINO, to achieve more accurate predictions; 3) Introducing an adaptive weighting mechanism based on confidence levels to aggregate the outcomes from different prediction methods. Experimental results on multiple datasets, including CIFAR-10, CIFAR-100, and TinyImageNet, demonstrate that our model can significantly improve classification accuracy compared to single-model approaches, achieving AUROC scores above 96% across all test datasets, and notably surpassing 99% on the CIFAR-10 dataset.
翻译:暂无翻译