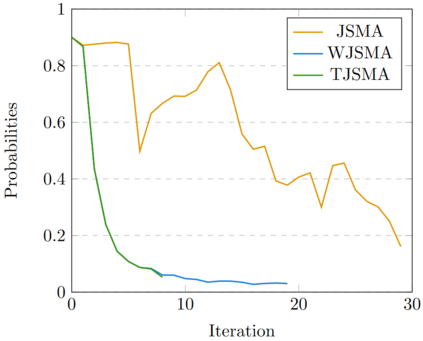
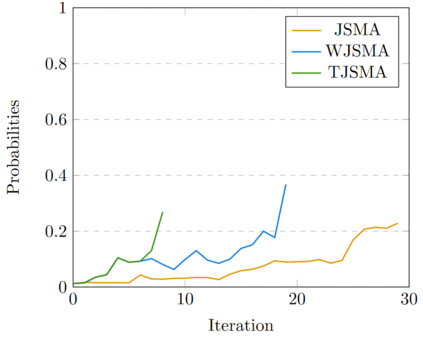
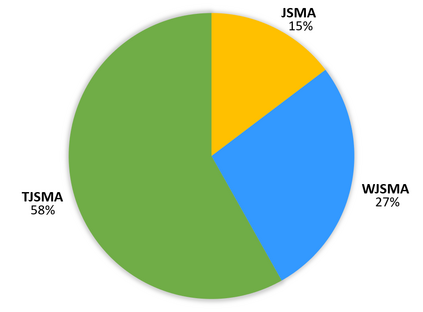
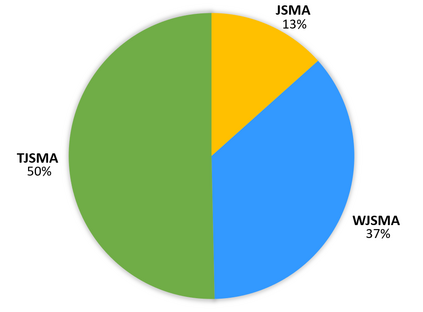
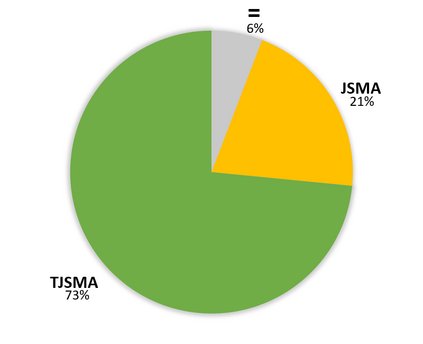
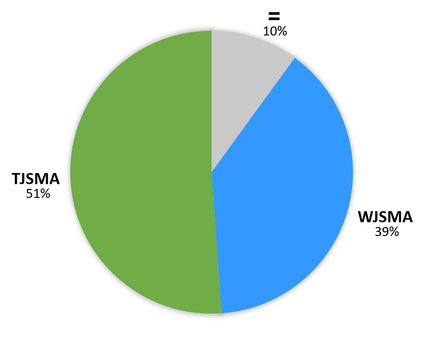
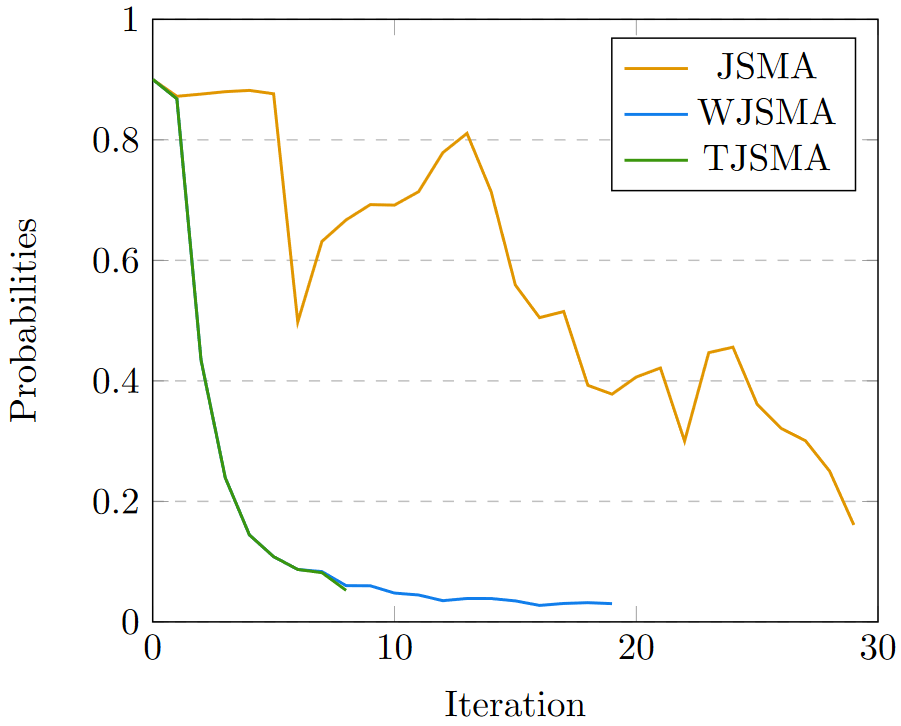
Neural network classifiers (NNCs) are known to be vulnerable to malicious adversarial perturbations of inputs including those modifying a small fraction of the input features named sparse or $L_0$ attacks. Effective and fast $L_0$ attacks, such as the widely used Jacobian-based Saliency Map Attack (JSMA) are practical to fool NNCs but also to improve their robustness. In this paper, we show that penalising saliency maps of JSMA by the output probabilities and the input features of the NNC allows to obtain more powerful attack algorithms that better take into account each input's characteristics. This leads us to introduce improved versions of JSMA, named Weighted JSMA (WJSMA) and Taylor JSMA (TJSMA), and demonstrate through a variety of white-box and black-box experiments on three different datasets (MNIST, CIFAR-10 and GTSRB), that they are both significantly faster and more efficient than the original targeted and non-targeted versions of JSMA. Experiments also demonstrate, in some cases, very competitive results of our attacks in comparison with the Carlini-Wagner (CW) $L_0$ attack, while remaining, like JSMA, significantly faster (WJSMA and TJSMA are more than 50 times faster than CW $L_0$ on CIFAR-10). Therefore, our new attacks provide good trade-offs between JSMA and CW for $L_0$ real-time adversarial testing on datasets such as the ones previously cited. Codes are publicly available through the link https://github.com/probabilistic-jsmas/probabilistic-jsmas.
翻译:众所周知,神经网络分类(NNCs)很容易受到恶意对抗性干扰投入的干扰,包括修改一小部分输入特征(称为稀释或0.00美元袭击)的干扰。有效和快速的L_0美元袭击,如广泛使用的JacobianSaliency Saliency Mape攻击(JSMA)对愚弄NNCs(JSMA)来说是实用的,但也有助于提高其稳健性。在本文中,我们通过产出概率和NNNCSN输入特征对JSMA的突出地图进行处罚,从而获得更强大的攻击算法,更好地考虑到每项输入的特性。这导致我们引入了更完善的JSMA(WSMA)和Taylor JSMA(JSMA)的网络版本(JSMA),通过三套不同的数据集(MITS、CIFAR-10和GTSRRRRB)进行各种白箱和黑箱实验,表明这些地图比最初的有目标和非目标版本要快得多。 实验还表明,在某些情况中,我们攻击的SMA-RO_SMalalalalal(比SMA(C_CRB_CR)比SBR)比尚更具有激烈的SM_C_C_CRDRD_C_CRBR_C_CR_R)比尚更快。