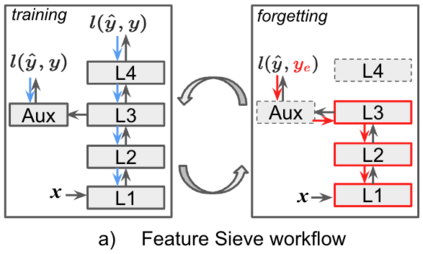
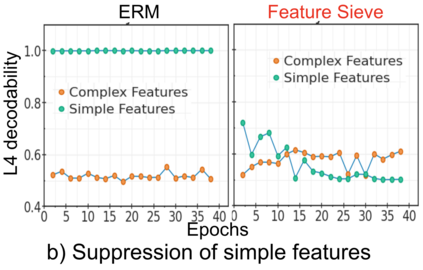
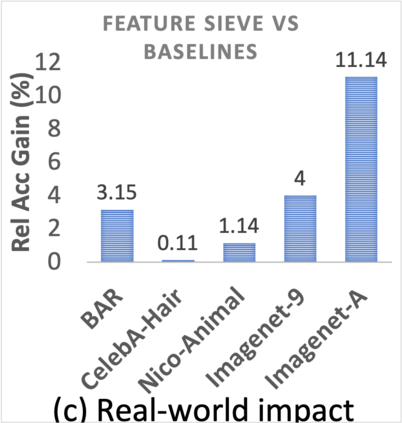
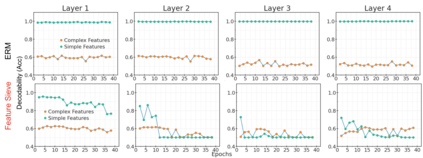
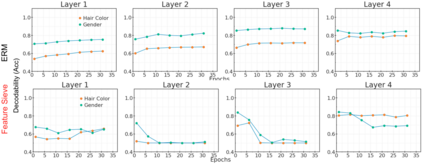
Simplicity bias is the concerning tendency of deep networks to over-depend on simple, weakly predictive features, to the exclusion of stronger, more complex features. This is exacerbated in real-world applications by limited training data and spurious feature-label correlations, leading to biased, incorrect predictions. We propose a direct, interventional method for addressing simplicity bias in DNNs, which we call the feature sieve. We aim to automatically identify and suppress easily-computable spurious features in lower layers of the network, thereby allowing the higher network levels to extract and utilize richer, more meaningful representations. We provide concrete evidence of this differential suppression & enhancement of relevant features on both controlled datasets and real-world images, and report substantial gains on many real-world debiasing benchmarks (11.4% relative gain on Imagenet-A; 3.2% on BAR, etc). Crucially, we do not depend on prior knowledge of spurious attributes or features, and in fact outperform many baselines that explicitly incorporate such information. We believe that our feature sieve work opens up exciting new research directions in automated adversarial feature extraction and representation learning for deep networks.
翻译:暂无翻译