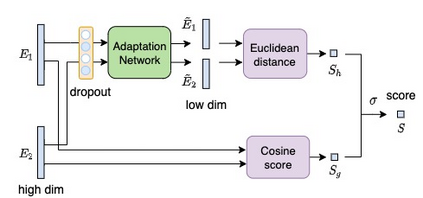
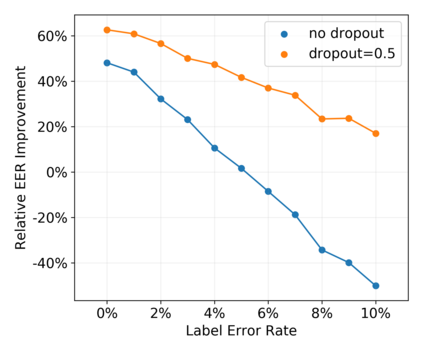
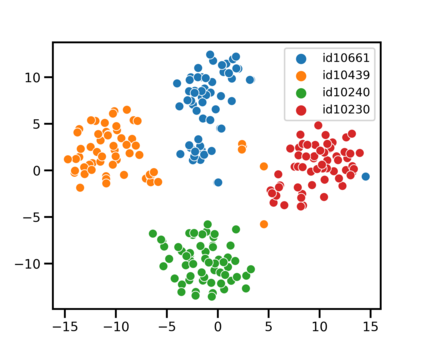
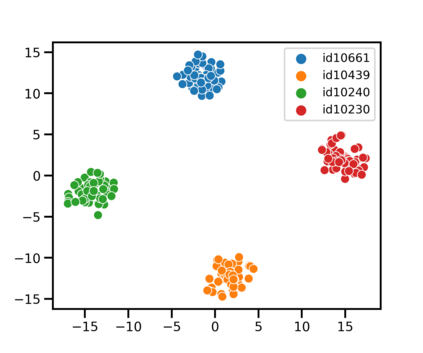
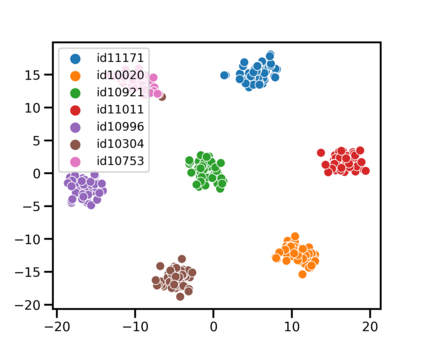
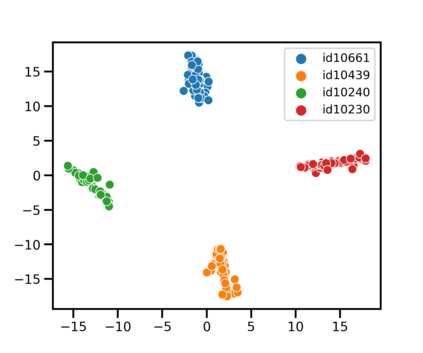
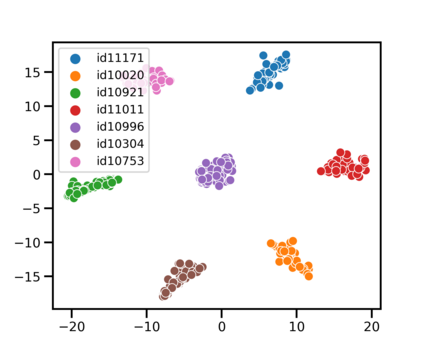
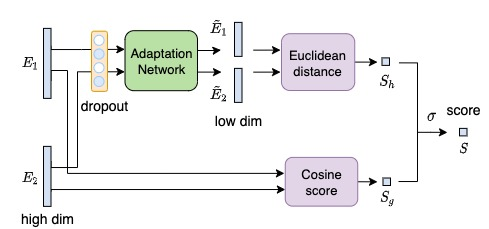
Speaker identification typically involves three stages. First, a front-end speaker embedding model is trained to embed utterance and speaker profiles. Second, a scoring function is applied between a runtime utterance and each speaker profile. Finally, the speaker is identified using nearest neighbor according to the scoring metric. To better distinguish speakers sharing a device within the same household, we propose a household-adapted nonlinear mapping to a low dimensional space to complement the global scoring metric. The combined scoring function is optimized on labeled or pseudo-labeled speaker utterances. With input dropout, the proposed scoring model reduces EER by 45-71% in simulated households with 2 to 7 hard-to-discriminate speakers per household. On real-world internal data, the EER reduction is 49.2%. From t-SNE visualization, we also show that clusters formed by household-adapted speaker embeddings are more compact and uniformly distributed, compared to clusters formed by global embeddings before adaptation.
翻译:发言人身份通常分为三个阶段。 首先,前端发言人嵌入模式经过培训,可以嵌入话语和发言者简历。 其次,在运行时间发言和每个发言者简历之间应用评分功能。 最后,根据评分标准,确定发言者使用最近的邻居。为了更好地区分在同一住户内共用一个装置的发言者,我们建议用一个家庭适应的非线性绘图到一个低维空间,以补充全球评分指标。组合评分功能在标签或假标签的发言者口语中优化。随着投入的放弃,拟议的评分模式将模拟住户的EER减少45-71%,每户2至7位难以区分的发言者。在现实世界的内部数据中,EER的减少率为49.2%。从T-SNE可视化中,我们还显示,由家庭适应的发言者嵌入成的集群比适应前全球嵌入的集群更加紧凑和统一分布。