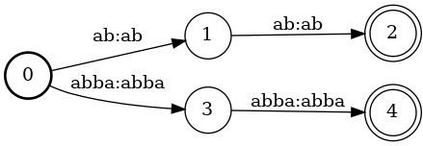
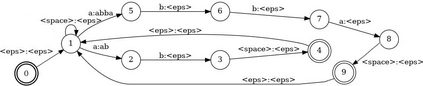
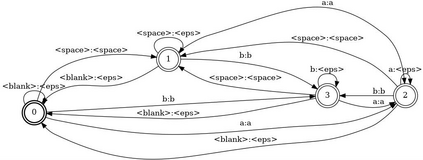
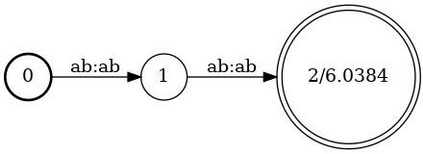
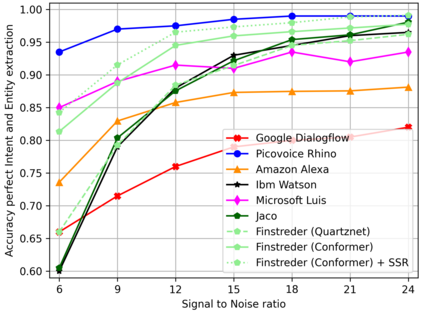
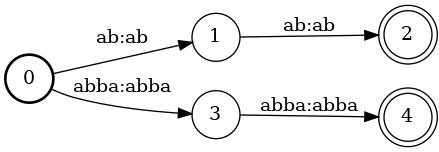
In Spoken Language Understanding (SLU) the task is to extract important information from audio commands, like the intent of what a user wants the system to do and special entities like locations or numbers. This paper presents a simple method for embedding intents and entities into Finite State Transducers, and, in combination with a pretrained general-purpose Speech-to-Text model, allows building SLU-models without any additional training. Building those models is very fast and only takes a few seconds. It is also completely language independent. With a comparison on different benchmarks it is shown that this method can outperform multiple other, more resource demanding SLU approaches.
翻译:在口语理解(SLU)中,任务是从音频指令中提取重要信息,比如用户想要系统做什么的意图,以及诸如地点或数字等特殊实体。本文为将意图和实体嵌入非限制性国家传输器提供了一个简单的方法,并与预先培训的通用语音到文字模式相结合,允许在不受过任何额外培训的情况下建立SLU模型。建立这些模型非常快,只需要几秒钟。它也是完全独立的语言。通过对不同的基准进行对比,它表明这种方法可以比其他需要更多资源的 SLU 方法更优于其他方法。