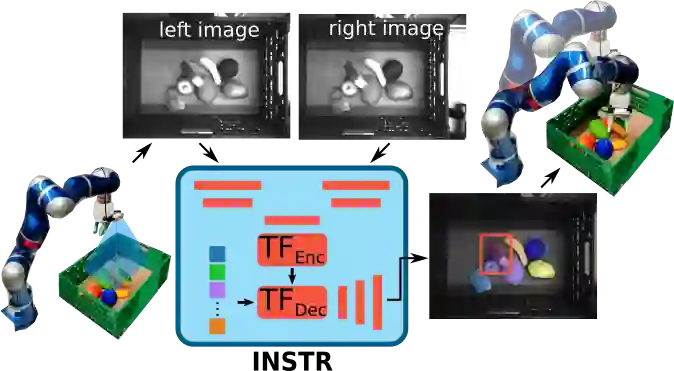
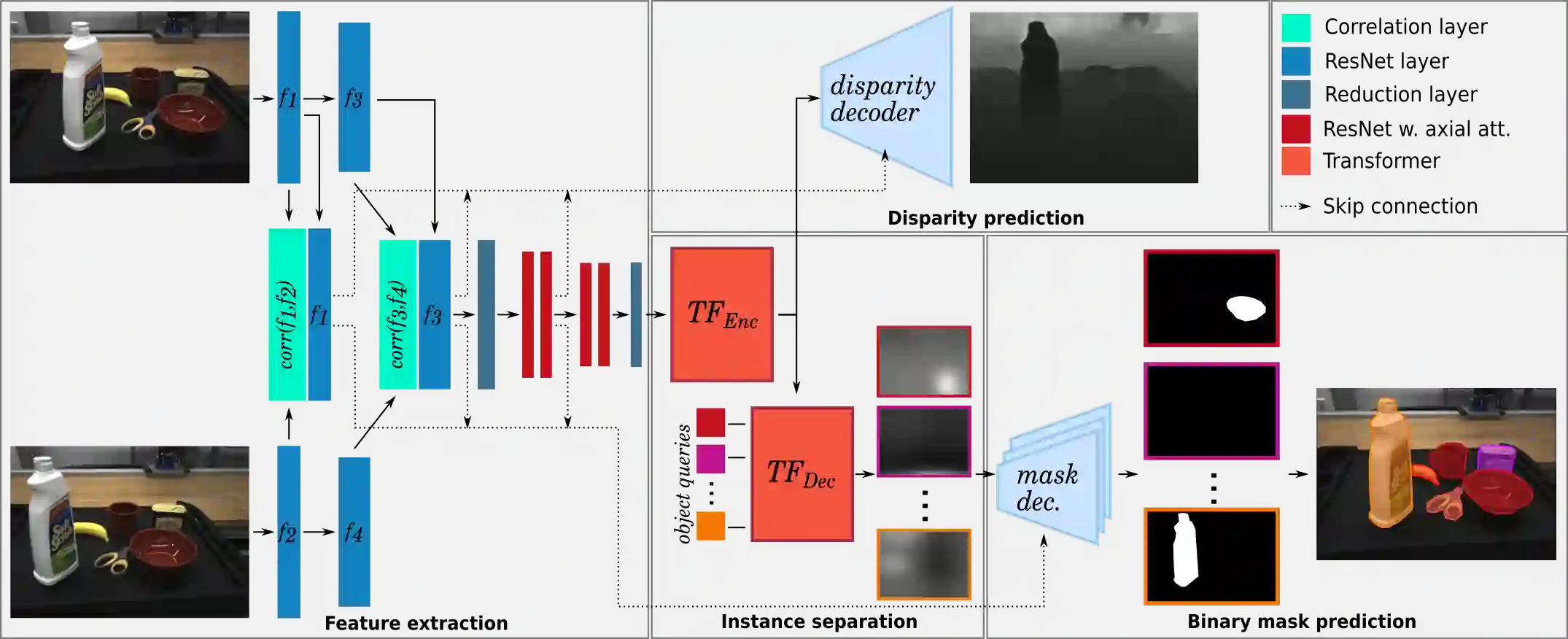
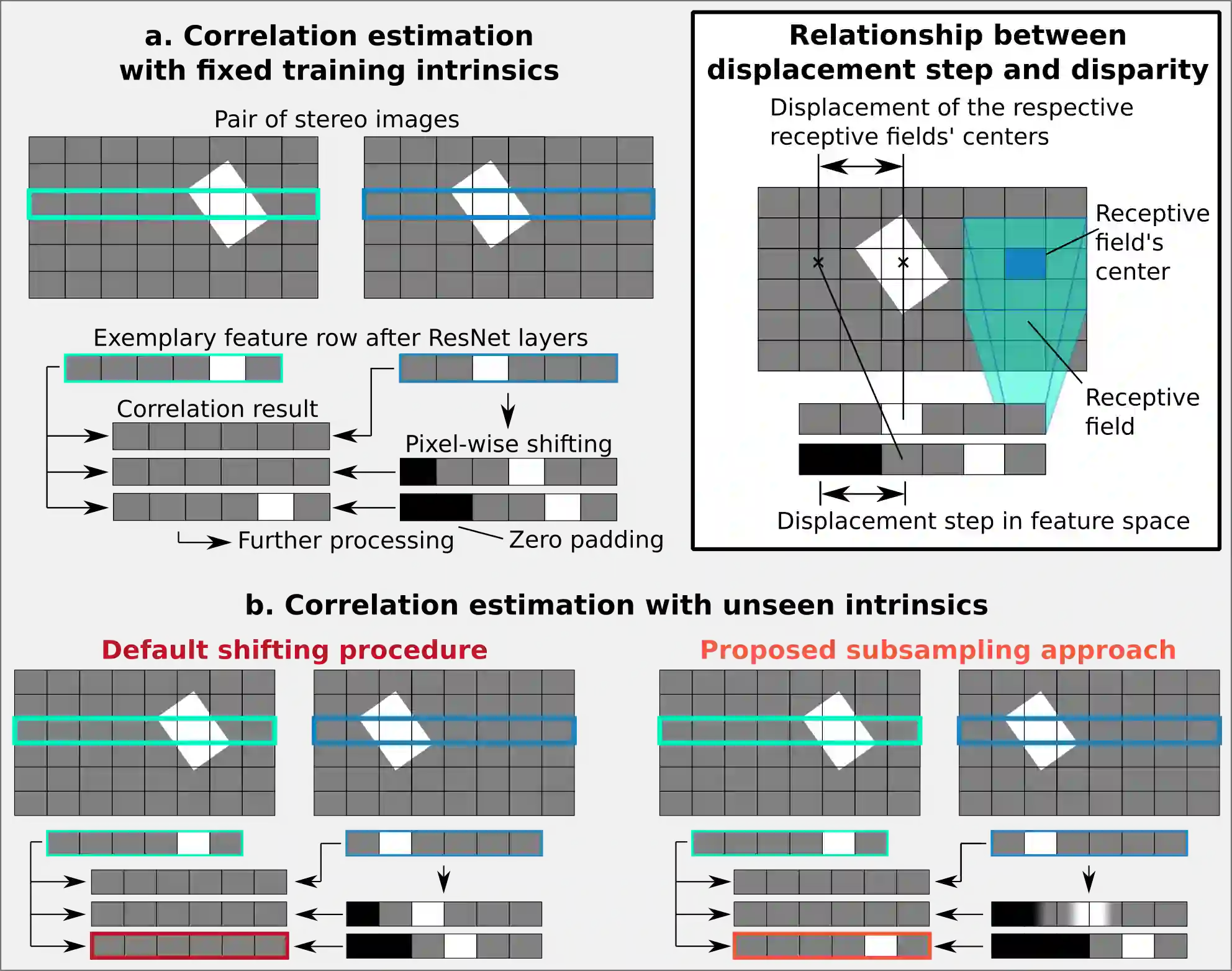
Although instance-aware perception is a key prerequisite for many autonomous robotic applications, most of the methods only partially solve the problem by focusing solely on known object categories. However, for robots interacting in dynamic and cluttered environments, this is not realistic and severely limits the range of potential applications. Therefore, we propose a novel object instance segmentation approach that does not require any semantic or geometric information of the objects beforehand. In contrast to existing works, we do not explicitly use depth data as input, but rely on the insight that slight viewpoint changes, which for example are provided by stereo image pairs, are often sufficient to determine object boundaries and thus to segment objects. Focusing on the versatility of stereo sensors, we employ a transformer-based architecture that maps directly from the pair of input images to the object instances. This has the major advantage that instead of a noisy, and potentially incomplete depth map as an input, on which the segmentation is computed, we use the original image pair to infer the object instances and a dense depth map. In experiments in several different application domains, we show that our Instance Stereo Transformer (INSTR) algorithm outperforms current state-of-the-art methods that are based on depth maps. Training code and pretrained models will be made available.
翻译:尽管体能感知是许多自主机器人应用的关键先决条件,但大多数方法仅部分地侧重于已知的物体类别来解决这个问题。然而,对于在动态和杂乱环境中互动的机器人,这不现实,严重限制了潜在应用的范围。因此,我们建议采用新的物体感知度分解方法,不需要事先对物体提供任何语义或几何信息。与现有工作相比,我们没有明确使用深度数据作为输入,而是依靠洞察到微微的视图变化,例如由立体图像配对提供的微小的视图变化,往往足以确定对象边界,从而确定分块对象。我们以立体传感器的多功能为重点,我们使用基于变压器的架构,直接从输入图像组合绘制到对象实例的图像。这具有主要优势,即不要求事先对物体进行音响和可能不完整的深度地图作为输入,我们使用原始图像配对来推断对象实例和密集深度地图。在几个不同的应用领域进行的实验中,我们展示了我们的立体变换器(INSTK)变换器(INSTRA)的算法将直接绘制当前状态模型。